november 30, 2012
Byte av epostadress, samt annat
Äntligen - säger kanske någon - så kommer det något livstecken från Håkan. Den som säger så har i så fall missat följande livstecken:
- My Constraint Programming Blog (uppdateras typ någon/några gånger i månaden)
- Arrays in Flux (som i och för sig mest innehåller gamla livstecken)
- hakank.org som innehåller - men odaterade - tecken om olika saker som gjorts (den senaste - i skrivande stund - tiden har det varit rätt mycket lekande med nya - för mig - programspråk och liknande).
Men - "tyvärr" kanske någon säger, eventuellt samma någon som ovan nämnda någon - så är denna blogpost endast (fast nästan) för att meddela den viktiga information att jag numera helt gått över till en annan epostadress, nämligen hakank@gmail.com. Detta eftersom Bredbandsbolaget helt och hållet stänger trotjänaren bonetmailen-adressen som varit med i nästan exakt 10 år (tack för denna tid, för övrigt).
Dock, för att ni inte ska gå helt tomhänta härifrån så kan meddelas följande - till viss del helt orelaterade - saker, fast ändå inte eftersom sak numro 2 är väldigt relaterad, på vissa sätt och vis i alla fall:
Språkligheter
Följande ord innehåller vokalernaa,e,i,o,u,y i ordning:
-
accelerationsmunstycke -
satellitkommunikationssystem
Detta ord innehåller vokalerna a,e,i,o,u,y,å,ä,ö i ordning:
-
satellitkommunikationssystemåtgärdsförslag
Och ordet tryckutjämningsbehållare är det ord (från den ordlista som be-sökts)
som innehåller flest olika bokstäver (20 stycken). Här är deras fördelning:
- a: 1
- b: 1
- c: 1
- e: 2
- g: 1
- h: 1
- i: 1
- j: 1
- k: 1
- l: 2
- m: 1
- n: 2
- r: 2
- s: 1
- t: 2
- u: 1
- y: 1
- å: 1
- ö: 1
Och följande ord är de som innehåller flest distinkta bokstäver, exakt en förekomst alltså (16 unika bokstäver)
utifrån densamma ordlista:
- giftermålsanbud
- ishockeyförbund
- jämlikhetsfråga
- oförvansklighet
Se nedan under "Senare not" för en senare not om detta.
Byte av mailadressen
Men - kanske någon kunde säga om just denne någon är bevandrad i data(sv)engelska -: Men hördudu Håkan,byte har ju en engelsk betydelse också, har du tänkt på det?. Varpå jag i så fall kunde svara: Ah, kul du tänkte på det! Det tänker man ju inte på om man bara säger ordet högt., och skulle då därefter kunna beskriva en algoritm för just denna betydelse av "byte av mailadress", nämligen transformeringen av hakank@gmail.com till en byte: Byt (sic!) ut varje bokstav till dess ASCII-värde, summera dess värden tillsammans och på denna summa gör man sedan en fin modulo Varpå man skulle kunna implementera algoritmen i programspråket K (om man hade den inklinationen och det har man ju ibland, eller hur?): (+/{_ic x}'"hakank@gmail.com")!255
43
(+/{_ic x}'"hakank@gmail.com")!256
37
(K är - för övrigt och som eventuellt kan ses med ovanstående kodexempel - ett väldigt uttrycksfullt "array language" som gör att man mycket kärnfullt kan uttrycka sina innersta tankar kring vissa saker i tillvaron, t.ex. saker såsom saker av ovanstående problemstruktur. Språket är en del i APL-familjen och typ en kusin till programspråket J. Hittills har K varit mer favoritspråk än J, men det är möjligt att detta ändras vad det lider.)
Senare not:
Samma person som påpekade (i ett mail som tyvärr - synnerligen felaktigt - ansetts av Google som spam) att det ska vara modulo 256 istället för 255, gav även förslaget "mödoutvecklingsbar" som ett längre ord med unika bokstäver än ovanstående. Även densamma person ansåg att det föreslagna ordet är "lite krystad, kanske" och påpekade att ordet inte fanns i Googles sökmotor; och det måste vi ju ändra på.
Slut senare not
Posted by hakank at 08:59 EM Posted to Diverse | Personligt | Program | Pyssel | Språk
augusti 30, 2009
The Pop-11 programming language and Poplog environment
First I must apologize for the Swedish readers for including an english text here: Sorry about that. I may do it again, but this blog has not permanently gone English. It has, however, changed its focus somewhat in other ways from the start in june 2003.Pop-11 and its environment Poplog is relatively unknown, originally designed for research and education in artificial intelligence. From What is Poplog:
Poplog is an integrated toolkit providing a highly extendable collection of languages and tools for teaching, research and development. By default it includes incremental compilers for three powerful AI programming languagesHere I will mostly write about the programming language Pop-11, but also mention how it is possible to integrate Pop-11, Prolog, and Lisp. See the programs below.
* Pop-11--the core language -- used to implement itself and the others;
* Common Lisp; and
* Prolog;
as well as
* Standard ML, a widely used functional language.
...
Most of Poplog is implemented in Pop-11, including the incremental compilers for all four languages and the integrated programmable editor.
Pop-11/Poplog is a huge system which includes - besides the four languages mentioned above and the VED editor which is also used for the help/teach system - much material for learning the system, as well as learning artificial intelligence. "Huge" above refers to the content of the system, not to the actual memory "footprint". For more about the size, see the entry Size at the Free Poplog page.
The language Pop-11 is Lisp-like in its approach but uses an Algol-like syntax. It has many of my favorite features of a programming language:
- interactive environment
- array/list comprehension
- pattern matching (on lists), and supports regular expressions
- functional programming, higher order functions
- multi-paradigm approach
- arbitrary precision
Some larger teaching examples
Here are some examples of the teach/help files. Many of these shows how to use a specific library, and some of them just teaches an artificial intelligence concept.- Eliza, the famous Eliza program
- Analogy/Evans, Evans' Analogy program (simplified version)
- Poprulebase, rule based database, e.g. for expert system
- Objectclass, object oriented programming
- database, database for pattern matching etc
- matcher, the basic pattern matcher
- super, an extension of pattern matching in Pop-11's database super_example, more about SUPER
- grammar analysing sentences
- solver: a GPS and (General Problem Solver), STRIPS like solver
- solvems: another problem solving library
- storygrammar, generation of sentences given a grammar
- schemata
- SimAgent TOOLKIT,
- lists, how to use lists
Documents and links
- Free Poplog Portal
- Teaching material
- Primer, probably the best way of start to learning Pop-11
- Robin Popplestone's Pop-11 book (draft)
-
- Rosetta Code: Pop-11
- Poplog online
- Wikipedia: Pop-11
- Mike Sharples, David Hogg, Chris Hutchison, Steve Torrance, David Young: Computers and Thought: A practical Introduction to Artificial Intelligence, online book on artificial intelligence using Pop-11 as programming language
- comp.lang.pop FAQ
- Wikipedia: POP-11
- Jocelyn Paine in Dr Dobbs 'Dobbs Code Talk' (Mars 2009): Poplog, continuations, Eliza, AI education, and Prolog
Mailing lists
My Pop-11/Poplog page
My Pop-11/Poplog page contains some of my Pop-11 programs. Some of them are the "mandatory" programs I always implement when learning a new programming language.Some of the program below requires functions from the GOSPL (Global Open Source Poplog Library) library, such as
split, split_with. GOSPL was available from www.poplog.org, but that site seems to be defunct right now. The library is now available from www.cs.bham.ac.uk/research/projects/poplog/, or more specific here: gospl_1_2_0.tar.gz
- init.p
init.p: My init.p file. - compiling
compile_test.p demonstres how to:
- compile a Pop-11 program to a saved (.psv) image,
- compile to an executable program.
Note: This was tested on a Linux machine (Mandriva). - Concordance
concord.p: Reads a file and show the number of occurrence of the words (sorted in order of occurrence). Requires GOSPL (see above). - Project Euler
euler_project.p: My Pop-11 solutions of the first 16 Euler Project problems. Requires newmemo.p, and GOSPL (see below). A note about the style in this program: When learning a programming language which has an interactive shell, I tend to use one-liners and array comprehension a lot. Especially in this case, since I used much of the principles used from my Lisp programs (usingloopa lot). - join (string)
join.p is a small utility function to join the characters of a string.
Syntax:join(string, separator)
e.g.join('hello,world','|')results inh|e|l|l|o|,| |w|o|r|l|d. This is used for example in read_test.p. - Lisp in Pop-11
lisp_in_pop11_test.p demonstrates how to run (Poplog's) Lisp code in Pop-11. - Grammar generation (swedish)
mygram.p generates some swedish (nonsense) sentences given a simple grammar and lexicon. It uses the GRAMMAR library (which includes a simple english grammar and lexicon).
The generating sentences is presented first as a parse tree, then the sentence.** [s [np [snp_t [det_t ett] [adj_t svagt] [adj_aux_t [fastän trött]] [noun_t handsfack]]] [vp [verb [grävde ned]] - [verb_aux [utan vett och sans]] - [np [snp_n [det_n en] [noun_n buske]]]]] ;;; The sentence: ** ett svagt [fastän trött] handsfack [grävde ned] - [utan vett och sans] - en buske. ;;; Flattened ** ett svagt fastän trött handsfack grävde ned - utan vett och sans - en buske.Which may be translated as something likea weak although tired glove department dug down - without wit or sense - a bush
Also, see tparse_test_swe.p mentioned below for generating the parse tree from this sentence. - Memo function
newmemo.p defines a Memo function (from Robin Popplestone's Pop-11 book) and use it for the Fibonacci sequence. - N-puzzle
n-puzzle.p: 8-puzzle and 15-puzzle, etc using the library SOLVEMS. - Pop-11 in Lisp
pop11_in_lisp_test.lsp: Simple demonstration how to run Pop-11 code in (Poplog's) Lisp. - Pop-11 in Prolog
pop11_in_prolog_test.pl: Simple demonstration how to run Pop-11 code in (Poplog's) Prolog. - Prolog in Pop-11
prolog_in_pop11_test.p: Simple demonstration how to run (Poplog's) Prolog code in Pop-11. - Primes / dynamic ("lazy") lists
primes.p generates prime numbers using a dynamic ("lazy") list. - Regular expressions
Pop-11 has regular expressions, albeit with a slighly different syntax than we are used to. The program read_test.p reads a word list and test each words against the regular expressions of consecutive characters, e.g. ".*a.*.b.*c.*" (in Pop-11 'a@.@*b@.@*c@.@*'), ".*b.*c.*d.*", ".*c.*d.*e.*", etc.
Using the standard Linux wordlist/usr/dict/wordsif found no word where there are 6 consecutive letters, but there are many of length 5. e.g.** [Testing abcde a@.@*b@.@*c@.@*d@.@*e] ** [abecedaire abecedaries abjectedness aborticide absconded abscondedly abscondence absconder absconders abstractedness ambuscade ambuscaded ambuscader ambuscades ambuscadoed amebicide amoebicide bambocciade bambochade carbacidometer Cerambycidae nonabstractedness Oxylabracidae scabicide unabstractedness] Counter: 25 ... ** [Testing qrstu q@.@*r@.@*s@.@*t@.@*u] ** [quasi-respectful quasi-respectfully] Counter: 2 ...Using a swedish wordlist I found some words of 6 consecutive characters.** [Testing klmnop k@.@*l@.@*m@.@*n@.@*o@.@*p] ** [alkoholmonopol kaliumtetracyanokuprat kaliumtetracyanoplatinat komplemento peration kulminationspunkt vinkelmätningsmikroskop]
This program requires join.p. - String matching, strmatches
read_test_strmatches.p: Read a word list and test each words against a string pattern of consecutive characters. Same as read_test.p (see above), but uses the strmatches function (not in the standard Poplog distribution). This version is much slower than using regular expression. Also, see comments below aboutstrmatches. - Solver: Banana problem
solver_banana_problem.p: (GPS) Banana problem using SOLVER library (schema and problem from Norvig "Paradigms of Artificial Intelligence Programming"). - Solver: Block worlds
solver_blocks_world.p: (GPS) Blocks world problem using SOLVER library (schema and problem from TEACH SOLVER). - Solver: Maze problem
solver_maze_problem.p: (GPS) Maze problem using SOLVER library (schema and problem from Norvig "Paradigms of Artificial Intelligence Programming"). - Solver: School problem
solver_school_problem.p: (GPS) School problem using SOLVER library (schema and problem from Norvig "Paradigms of Artificial Intelligence Programming"). - Timing
timing_test.p: Two timing functions which only run the procedure once (as opposed to the builtintimingwhich runs many times). One definition is a syntax word, the other is a procedure proper. Includes a simple test. - Parsing (swedish text)
tparse_test_swe.p: Parses (simple) swedish sentences given a simple grammar and lexicon. Uses the TPARSE library.
Continuing from the grammar example above:listparses("s", [ett svagt [fastän trött] handsfack [grävde ned] [utan vett och sans] en buske])==> ** [[s [np [snp_t [det_t ett] [adj_t svagt] [adj_aux_t [fastän trött]] [noun_t handsfack]]] [vp [verb [grävde ned]] [verb_aux [utan vett och sans]] [np [snp_n [det_n en] [noun_n buske]]]]]]
Installation
This is how I install Pop-11/Poplog when a new version arrives. I run on a linux and the current_poplog directory is a symbolic link to the actual latest distribution directory. Here I assume that the version isv15.63.
- move the previous installation, e.g.
rm current_poplog # this is a link mv v15.63 v15.63.old
- Download the latest version of
./get-and-install-v15.63-poplog-here(or whatever version) from http://www.cs.bham.ac.uk/research/projects/poplog/v15.63/#installing. -
chmod +x get-and-install-v15.63-poplog-here -
./get-and-install-v15.63-poplog-here - After the installation:
ln -s v15.63 current_poplog - Fetch the latest contrib.tar.gz
Unpack and copy in
current_poplog/pop/v15.63/pop/packages/contrib/
Posted by hakank at 09:26 FM Posted to Program | Comments (1)
augusti 30, 2008
Ubiquity 0.1 - kommandoradsfunktionalitet i Firefox
Den senaste veckan har det pratats en del om version 0.1 av Firefox-tillägget Ubiquity från Mozilla Labs. Här är några kommentarer efter en första sittning.
Och det är helläckert!
Med en enkel tangentbordskombination (Alt-mellanslag i min Firefox 3.0 + Mandriva Linux) får man upp en "kommandorad" där man kan skriva in kommandon. Detta kallas för "Ubiq", vilket på svenska torde bli "att ubiqa" (eller möjligen "att ubika").
En mycket trevlig introduktion av funktionaliteten, inklusive en kort video, görs i Introducing Ubiquity.
Exempel
Här är några enkla exempel på hur man kan använda Ubiquity. Fler - och mer avancerade - exempel finns i User Tutorial.
google
google Ubiquity
gör en googlesökning på sökfrasen "Ubiquity".
this
Stöter man på en fras (t.ex. "constraint programming") kan man markera den och sedan ubiqa med
wiki this
varpå en Wiki-sökning görs. this avser det markerade området:. Man skriver alltså this.
translate
Markera en engelsk fras och ubiqa
translate this from english to swedish
Översättningen visas redan i previewfältet så man behöver inte ens exekvera kommandot. Riktigt trevligt.
Den finns stöd för en massa andra sökmotorer etc. såsom Yahoo, IMDB etc.
Andra kommandon som är bra att känna till:
* command-list: Visar vilka kommandon som finns tillgängliga för tillfället i browsern, inklusive egentillverkade (se nästa avsnitt).
Skriva egna Ubiquity-kommandon
Naturligtvis vill man utöka reportoaren med egna Ubiquity-kommandon som skrivs i Javascript. Här är två enkla exempel som jag personligen kommer att använda.
Instruktioner hur man skapar egna kommandon finns i Author Tutorial, där det finns mycket mer avancerade saker än nedanstående.
För att testa kommandona använder man en webbaserad kommandoeditor via kommandot command-editor, där man skriver in kommandona. Man behöver inte göra något speciellt mer än skriva (eller klistra in) koden, saker sker automatiskt i bakgrunden.
Det första exemplet är en sökning på Bokus och den andra en sökning på knuff.se. Det är inte rocket science, men funkar. (Jag har inte laborerat med mer de avancerade preview-funktionerna speciellt mycket.)
makeSearchCommand({
name: "bokus",
url: "http://www.bokus.com/cgi-bin/book_search.cgi?FAST={QUERY}",
icon: "http://www.bokus.com/favicon.ico",
description: "Searches Bokus for your books, movies, and games.",
preview: function(pBlock, directObj) {
if (directObj.text)
pBlock.innerHtml = "Searches Bokus for " + directObj.text;
else
pBlock.innerHTML = "Searches Bokus for the given words.";
}
});
makeSearchCommand({
name: "knuff",
url: "http://knuff.se/q/{QUERY}",
icon: "http://knuff.se/favicon.ico",
description: "Searches knuff.se for phrases from the swedish blogosphere.",
preview: function(pBlock, directObj) {
if (directObj.text)
pBlock.innerHtml = "Searches knuff.se for " + directObj.text;
else
pBlock.innerHTML = "Searches knuff.se for the given words.";
}
});
Det enda man egentligen behöver veta för att göra liknande kommandon är sökurlen och sedan byta ut sökfrasen med {QUERY}.
Man kan nu testa detta med
bokus constraint programming
eller för att söka på ett ISBN som man ser hos sin favoritblogg: 9780140286809 . Märk detta och skriv
bokus this
(Boken har inget med Ubiquity att göra - mer än möjligen indirekt genom associationer.)
knuff Ubiquity
som ger följande resultat.
För mer persistent användning av kommandona, för att ge sina medmänniskor tillgång till dem - och eventuellt "prenumerera" för att få automatiska uppdateringar - bör man publicera koden någonstans på webben. Läs i Author Tutorial hur man gör detta.
Jag har dock inte publicerat någon sådan sida. Eventuellt kommer det senare.
Säkerhet
Genom Ubiquity får användaren tillgång till mycket avancerade funktioner i webbläsaren. Tyvärr kan (och kommer att) elaka människor utnyttja detta för sina elakheter. Det finns för närvarande (i Ubiquity 0.1) ett visst skydd genom att man man får se en stor fet varningsskylt innan man börjar prenumerera, men det är naturligtvis inte tillräckligt. Det talar om en framtida "web of trust" där användare kan rekommendera/varna för en speciell prenumeration. Vi får väl helt enkelt se...
Detta sagt, testa gärna funktionaliteten, men prenumerera inte på något som du inte känner till/litar på.
Några andra kommentarer
* Jag har inte fått
email eller add-to-calendar (stödjer endast Googles gmail/calendar) att fungera ordentligt.
* De speciella internationella tecknen (framförallt "å", "ä" och "ö") stökade i kommandot translate, möjligen är det något konstigt i min miljö...
* Vissa kommandon, t.ex. translate skriver in texten där (mus)markören befinner sig. Vad jag vet finns det inget sätt att ångra detta utan man måste ladda om sidan igen för att ta bort texten. Jag trodde att undo skulle göra det, men icke.
* Detta är version 0.1 och mycket kommer säkerligen att ändras...
* För övrigt påminner detta en del om programmeringsspråket/-miljön Rebol.
Länkar
Här är lite länkar om Ubiquity (varav några redan nämnts):
* Wiki: Ubiquity
Introducing Ubiquity
* Google-gruppen ubiquity-firefox
* User Tutorial
* Author Tutorial
* Forum
Posted by hakank at 10:18 EM Posted to Program | Sökmotorer | Comments (4)
september 27, 2006
Generering av Nobelpris-motiveringar (Markov såklart)
Nu ...
Nu har spekulationerna om Nobelpriset i litteratur börjat.
I stället för att gissa vem...
I stället för att gissa vem som kommer att få detta välansedda kulturpris har istället skrivits ett program som genererar motiveringar i syfte att efternå dessa de synnerligen elokventa språkliga konstruktionerna. Samtliga tidigare Nobelpris-motiveringar (litteraturpriset) finns hos Svenska akademien och är precis de som utgåtts ifrån i programmet.
Markovgenererade Nobelprismotiveringar (litteraturpriset)
Det nobelprismotiveringsgenererande programmet heter Markovgenererade Nobelprismotiveringar (litteraturpriset) och använder den här tidigare använda tekniken med Markovkedjor (se nedan för referenser).
Några slumpade exempel
Här är några slumpmässiga exempel på de av programmet genererade motiveringarna. Notera att orden "hans" respektive "hennes" har ersatts med "hans/hennes" så det är enkelt att bara kopiera-och-klistra texten och stryka endera val beroende på pristagarens kän, måhända efter ytterligare viss s.a.s. bearbetning av det givna materialet.
* för hans/hennes romankonstnärlig fulländning som med liknelser burna av fantastiska och levande i skildringen av människans belägenhet inom den dramatiska diktning som i nya former för roman buddenbrooks vilken stundom i sagospelets stora ryska berättarkonst som på självständigt besjälade diktning söker svar på människans belägenhet i en värld som genom en poesi som mot bakgrund av sinnlig styrka tolkat humana värden i tecknet av en historiska framställningskraft samt den skönhet och fantasifulla berättartradition levandegör en modern människans utsatthet
* för ett vidsträckt inflytande i vår vittskådande berättarkonst som infört en ny världsdel i litteratur
* för hans/hennes intensitet
Som kan ses ... (kommentar på ovanstående)
Som kan ses med viss men inte önskad tydlighet är inte alla förslag alldeles lysande. Därför presenteras flera förslag varje gång.
Parametern n (om parametern n)
Vad gäller parametern n (n såsom i n-gram) rekommenderas ett värde kring 5 eftersom ett betydligt högre värde ger i stort sett kopior av originaltexterna, och ett betydligt lägre ger gibberish (knappt igenkännlig svenska). Men experimentera gärna, det är precis sådant sådana här program är till för.
Man bör kanske notera... (om att n-gram har två något olika betydelser)
Man bör kanske notera att n-gram i dessa sammanhang har två något olika betydelser:
1) n är antalet ord som man arbetar med
2) n är antalet tecken (normalt bokstäver samt mellanslag, möjligen även siffror).
Ovan- och nedanstående program använder n-gram i den senare betydelsen, dvs arbetar på teckennivå. Det finns säkert någon tredje variant, men den är i så fall inte relevant. Ledsen om detta förvirrat någon läsare. Ledsen om denna kommentar ytterligare förvirrar samma eller andra läsare.
Se även
Automatisk identifikation av språk (språkidentifiering)
Bloggidentifiering (Blog Identification)
Magenta: När orden inte räcker till
Wikipedia: N-gram
Några andra program som använder samma teknik:
Andra bloggar om: nobelpris, litteratur, markovkedjor, generering av text.
Posted by hakank at 08:25 EM Posted to Program | Språk | Comments (3)
juni 23, 2006
Fotbollsmål i 3D: Virtual Replay
Förvånande nog (inte minst för mig själv) har jag faktiskt sett VM-fotbollen från början denna gång, och kanske än mer förvånande är att det inte bara är Sveriges matcher som följts utan även flera andra. Inte så att jag kan redogöra för alla detaljer kring matchen, men jag har i alla fall sett dem och har faktiskt haft en och annan synpunkt dagen efter.
Ett skoj program om man vill gotta sig i gjorda mål (eller o-gotta sig i dem beroende på matchsympatier) i 3D är det danska Virtual Replay (från dr.dk).
Programmet har flera roliga finesser såsom att man kan följa olika kameror och olika synvinklar. T.ex. kan man tydligt se Henkes målfot i sista England-målet genom följandde:
* välj först matchen (Grupp B, Swe - Eng)
* när matchen är inläst: välj "Henrik Larsson" uppe till höger (med svenska flaggan) och sedan "Spillerperspektiv: 11 Larsson", "Tredje person", "Hastighet 1/8".
* gotta sig
(Via information aesthetics.)
Andra bloggar om: fotboll, fotbollsmål.
Posted by hakank at 09:12 FM Posted to Program | Sport, idrott, hälsa | Comments (4)
juni 09, 2006
Utanvitsar (utangåtor, utanrebusar): ett program
Håkan Karlsson har beskrivit ett skoj ordpyssel i Utanvitsen, där det gäller att komma på vilket ordpar som avses utifrån en bokstav samt en liten beskrivning.
Några exempel:
k: barnlösa monarker ( = kungar utan ungar)
r: outvecklad kommunism (= revolution utan evolution)
r: torkade fikon (frukt utan fukt)
I kommentarerna ger Bloggblad följande paradigmatiska exempel (som Lotten Berglund löste elegant)
m = magerlagd engelsman (mister utan ister)
Läs mer underbara exempel hos hakke.
Mer schematiskt:
[bokstav]: "ord_X med [bokstav]" utan "ord_X utan [bokstav]"
Det kan även finnas mer strikta regler, t.ex. att [bokstav] måste finnas i början eller i slutet av ord_X (denna regel används i programmet som beskrivs nedani.
Programmet Utanvitsar
Efter och enligt önskemål från hakke har jag skrivit ett litet program för att underlätta konstruktionerna av själva utanvits-paren (som jag något fånigt kallar "utanvitskompisar"): Utanvitsar.
Ordlistan som används är på cirka 90 000 svenska ord.
Exempel på en körning
Ordet mister ger följande två kompisar:
* mister - ister
* mister - miste
Och ordet yra ger denna ansamling:
* fyra - yra
* hyra - yra
* lyra - yra
* myra - yra
* pyra - yra
* syra - yra
* yra - yr
För att underlätta konstruktionerna ännu mer har det skapats en fil med mer än 10 000 svenska sådana par (utifrån samma ordlista på cirka 90 000 ord som används i programmet): utanvitspar_swe.txt. Filen innehåller även ordböjningar som näppeligen är speciellt skojiga (t.ex. "frostskadad - frostskada").
Med ett enkelt handgrepp kan man även få engelska utanvitskompisar (without pal pairs?).
Noter
Not 1
Programmet söker endast efter utanvits-kompisar som kan skapas genom att första eller sista bokstaven tas bort/läggs till. Detta innebär att kombinationen "frukt - fukt" inte kommer med. Denna begränsning är helt enligt hakkes önskemål.
Not 2
Det är inte alls säkert att det finns en sådana kompisar för det givna ordet.
Not 3
Den där beskrivningen som följer efter den ensamma bokstaven - som helst ska vara poängfull och förvirrande och om möjligt med en samhällstillvänd udd - får man själv komma på.
Posted by hakank at 09:39 EM Posted to Program | Pyssel | Språk | Comments (1)
april 22, 2006
Divisorträd: unika sätt att göra konsekutiva uppdelningar
Vilka - och hur många - unika sätt kan man göra följande "konsekutiva delningar" av ett antal saker. Tänk t.ex. på de olika unika sätt man kan dela upp N antal spelkort i olika högar. Metoden man arbetar med är följande:
- börja med en hög av N saker
- dela upp dessa saker i ett antal högar så att det är lika många saker i varje hög
- ta en av dessa högar och fortsätt på samma sätt tills det bara finns
en sak i varje hög
Eller på ett något mer matematiskt språk: på vilka - och hur många - olika unika sätt man kan dela upp ett tal i dess divisorer (förutom 1 och talet själv).
Not: Eftersom nedanstående inte har (matematiskt) bevisats så är det endast en hypotes (en förmodan).
Uppdatering. Hmm, jag har hittat en inkonsekvens i nedanstående. Inte bra. Återkommer...
Program: Divisor tree
Det program som används för att undersöka dessa konsekutiva delningar är Divisor tree / / Consecutive dealing in heaps. Nedanstående förklaringar är förhoppningsvis tillräckligt för att förklara programmet.
Notera att programmet endast arbetar med värden mellan 2 och (lite halv godtyckligt) 30000 av datorsnällhetsskäl.
Inledande exempel
Låt oss göra det mer åskådligt med 16 saker (t.ex. 16 spelkort).
För N = 16 finns det 4 olika sätt.
16 / 2 heaps = 8 things in each heap (2 -> 8 -> ..)
8 / 2 heaps = 4 things in each heap (2 -> 4 -> ..)
4 / 2 heaps = 2 things in each heap (2 -> 2 -> 1)
8 / 4 heaps = 2 things in each heap (4 -> 2 -> 1)
16 / 4 heaps = 4 things in each heap (4 -> 4 -> ..)
4 / 2 heaps = 2 things in each heap (2 -> 2 -> 1)
16 / 8 heaps = 2 things in each heap (8 -> 2 -> 1)
Found 4 ways for N = 16.
Beskrivning av det första (unika sättet):
* Först har vi 16 saker.
* Dessa delas upp i två högar med 8 saker i varje hög.
* Vi tar en av dessa två högar och har nu en hög med 8 saker. Denna delar vi upp i 2 högar så vi får 4 saker i varje hög.
* Vi tar en av dessa högar och delar upp i 2 högar med två saker i varje hög.
* Vi tar sedan en av dessa högar och delar ut i 2 högar med 1 sak i varje hög.
Men sedan kan vi inte gå vidare eftersom det nu är endast 1 sak i varje hög. Man skulle i och för sig kunna dela upp 1 sak i 1 hög i det oändliga men det är inte tillåtet i detta spel. Regel: När det endast finns 1 sak i en (färdigutdelad) hög är man klar med denna uppdelnin.
Antal saker som fanns i de högar vi använder under utdelningen är: 16, 8, 4, 2, (1).
Tittar vi på exempelkörningen ser vi att en unik väg (ett unikt sätt) är avslutat om raden avslutas med -> 1. Står det däremot -> .. så fortsätter uppdelningen och man går vidare till nästa (inskjutna) rad. Denna trädliknande struktur är anledningen till att det kallas för divisorsträd där de olika uppdelningssätten grenar ut sig. (Möjligen skulle det kunna kallas för divisorsstad eftersom det är vägar vi pratar om eller divisorsskog efterom det är flera träd med olika grenar, men ingendera av dessa känns lika naturligt som -träd).
De 4 olika sätten för N = 16 är följande, där talen anger antal saker i varje hög. Den första raden motsvarar alltså den långa beskrivningen ovan.
16 -> 8 -> 4 -> 2
16 -> 4 -> 2
16 -> 4 -> 2
16 -> 8 -> 2
För N=12 finns det 5 vägar (avslutas med 2 eller 3)
12 / 2 heaps = 6 things in each heap (2 -> 6 -> ..)
6 / 2 heaps = 3 things in each heap (2 -> 3 -> 1)
6 / 3 heaps = 2 things in each heap (3 -> 2 -> 1)
12 / 3 heaps = 4 things in each heap (3 -> 4 -> ..)
4 / 2 heaps = 2 things in each heap (2 -> 2 -> 1)
12 / 4 heaps = 3 things in each heap (4 -> 3 -> 1)
12 / 6 heaps = 2 things in each heap (6 -> 2 -> 1)
Found 5 different way(s) for n = 12.
Primtal
Om det finns ett primtal antal saker i en hög finns det endast ett sätt (en väg) att dela upp i lika antal högar, nämligen att dela så att det finns en sak i varje hög. T.ex. om man har 13 kort så kan man endast dela ut dem i 13 olika högar med 1 kort i varje hög.
En väg avslutas alltså om det blir en hög innehåller primtal stycken saker. Eller mer korrekt: Om det är primtal antal stycken blir nästa uppdelning så många högar med 1 sak i varje hög.
Primtalskvadrater
För 4 saker så finns det bara ett sätt: nämligen att dela upp i två högar med två saker i vardera.
4 / 2 heaps = 2 things in each heap (2 -> 2 -> 1)
Found 1 different way(s) for n = 4.
Detta är ingen slump. För varje kvadrat av primtal (2^2=4, 3^2=9, 5^2=25, 7^2=49 osv) så finns det endast ett sätta att göra uppdelningen.
Båda dessa specialfall, primtal och primtalskvadrater utnyttjas i den rekursiva algoritm för att räkna ut antalet unika konsekutiva uppdelningar, och som beskrivs nedan.
Antal uppdelningar, heltalssekvenser
Om man nu räknar antalet unika sätt att göra denna typ av uppdelningar för N = 1.. 32 får vi följande heltalssekvens:
1,1,1,1,1,2,1,2,1,2,1,5,1,2,2,4,1,5,1,5,2,2,1,12,1,2,2,5,1,9,1,8
Här är en graf över sekvensen för N = 1 .. 512:
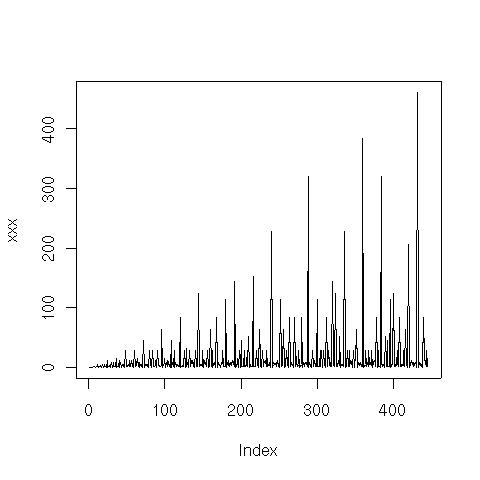
Ett bra sätt att analysera denna typ av matematiska (eller algoritmiska) strukturer är att se om det finns andra strukturer som har samma heltalssekvens. Det gör man lämpligen via On-Line Encyclopedia of Integer Sequences (som beskrivits tidigare i Heltalssekvenser). Ovanstående sekvens fanns inte med! Inte heller hittades sekvensen via superseeker som är en tjänst där man mailar in sekvensen och där systemet gör väldigt många olika typer av transformationer av sekvensen. Inte heller där hittades sekvensen.
Så det verkar som om ovanstående sekvens är ganska ovanlig. Lite märkligt eftersom det känns som en "naturlig" metod. Vi ser nedan att det är en "kusin" till en känd heltalssekvens.
Rekursiv definition
Ovanstående sekvens räknades ursprungligen ut genom att skapa vägarna i en tidig version av programmet Divisor tree, men sedan skapades (upptäcktes) en metod för att räkna ut dessa värden mycket enklare. Här är pseudokoden för metoden:
divtree(n):
# n > 0
if n == 1 then value = 1 # specialfall för n = 1
elsif prime(n) then value = 1 # primtal
else if prime_square(n) then value = 1 # kvadrat av ett primtal
else if # annars: loop igenom divisorerna av n
for div = divisors(n) do
next if div == 1 or div == n # se kommentaren nedan
value = value + divtree(div) # summera divisorernas värden rekursivt
return value
Notera raden med "next" i for-loopen. Den innebär att om divisorn är 1 eller n så adderar man inte något värde för denna divisor. (Det är genom att förändra next-raden som vi hittar sekvensens kusin. Se nedan) Notera också att det är en rekursiv definition.
Pratversionen av metoden är ungefär: Om N är 1, ett primtal eller en primtalskvadrat så finns det ett unikt sätt att göra en delning. Om N är något annat så summerar man divtree-värdena för N:s divisorer (alla divisorer förutom 1 och N själv).
Det tarvar kanske ett exempel på detta, så låt oss titta på N = 24 (dvs 24 saker). Först divisorsträdet:
24 / 2 heaps = 12 things in each heap (2 -> 12 -> ..)
12 / 2 heaps = 6 things in each heap (2 -> 6 -> ..)
6 / 2 heaps = 3 things in each heap (2
Posted by hakank at 11:09 FM Posted to Matematik | Program | Comments (2)
april 19, 2006
de Bruijn-sekvenser av godtycklig längd
För några år sedan skrevs ett program för att skapa de Bruijn-sekvenser, som kortfattat kan förklaras som en sträng (cykel) som innehåller ("testar") alla förekomster av delsträngar, där delsträngarna är representationer av tal. Mer förklaringar och exempel ges i de Bruijn-sekvenser (portkodsproblemet) och programmet de Bruijn sequence. I slutet finns även några andra referenser.
De metod som dessa sekvenser konstrueras ger endast stränglängder med jämna potenser, dvs 2^2 = 3, 2^3 = 8, 3^2 = 9, 3^3 = 27 osv. En fråga som ställdes tidigt var: Kan man skapa sådana sekvenser för en godtycklig längd, t.ex. 11, 17 eller 52 och för godtycklig bas, 2, 6,11 etc? Basen är alltså den kodning av talen man använder, där.basen 2 ger en binär representation (0,1), basen 3 använder 0, 1,2 osv.
Svaret på frågan är: Visst kan man det!
Än så länge har jag dock inte kommit på en vacker algoritm som den som finns för "vanliga" de Bruijn-sekvenser. Se The (Combinatorial) Object Server, Information on necklaces, unlabelled necklaces, Lyndon words, De Bruijn sequences (i slutet på sidan finns det länkar för att ladda ner källkod).
Programmet "de Bruijn arbitrary sequences"
Programmet de Bruijn arbitrary sequences visar några av resultaten av denna undersökning. Troligen behövs lite förklaringar av programmets metoder och parametrar och sådant bistår jag så gärna med.
Metoden: slumpa cykler
Principen för att skapa dessa sekvenser är enkel: Skapa en de Bruijn-graf och slumpa fram cykler i denna graf tills en av korrekt längd hittas.
Denna slumpmässighet är det som gör att programmet inte tillåts arbeta med speciellt stora värden.
de Bruijn graf
En de Bruijn-graf är en graf där kopplingarna mellan talen (noderna) följer "de Bruijn-regeln" att ett tals suffix ska vara ett annat tals prefix i deras *-ära representation. T.ex. det binära talet 000 kan kopplas till 001, talet 001 med 010 och 011 osv. Baser större än 2 hanteras på motsvarande sätt.
Exempel: Här visas kopplingarna i grafen för n = 16 i basen 2. Inom parentes visas den binära representation av talet.
0: 0 1 (0000)
1: 2 3 (0001)
2: 4 5 (0010)
3: 6 7 (0011)
4: 8 9 (0100)
5: 10 11 (0101)
6: 12 13 (0110)
7: 14 15 (0111)
8: 0 1 (1000)
9: 2 3 (1001)
10: 4 5 (1010)
11: 6 7 (1011)
12: 8 9 (1100)
13: 10 11 (1101)
14: 12 13 (1110)
15: 14 15 (1111)
Här är en mer grafisk representation (skapat med programmet dot).
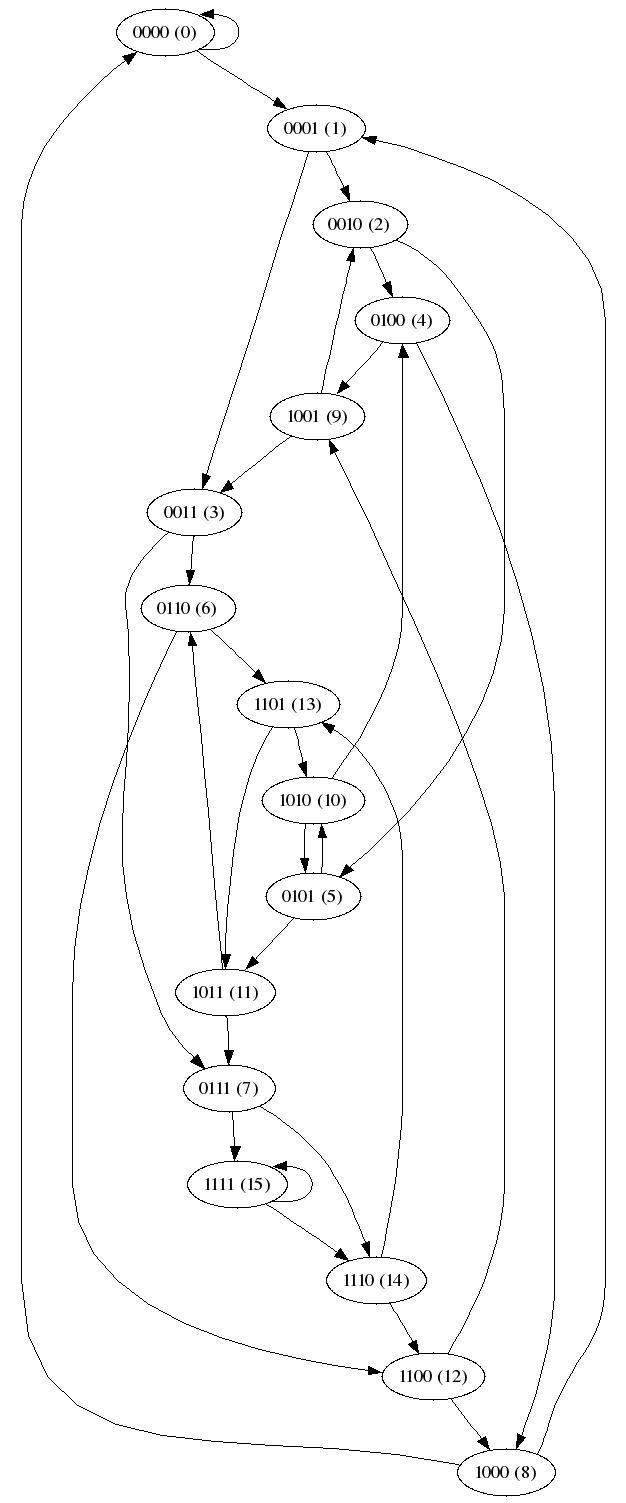 (klicka på bilden för att förstora den).
(klicka på bilden för att förstora den).
Antalet noder
Antalet noder i de Bruijn-grafen räknas ut enligt följande (motsvarar nearest_power i pseudo-koden nedan):
- om n är en jämn potens för basen används n noder (talen 0..n-1). T.ex. n=16 bas 2 är 2^3 är en sådan jämn potens.
- annars är antalet noder den närmaste efterföljande jämna potensen för basen. Exempel: För n=7 (bas 2) blir det 8 noder (2^3=8 ). För n=21 bas 3 blir det 27 noder (3^3=27 ) osv.
Kopplingsgrafen är enkel att räkna ut och principen ses nog vid närmare granskning av några exempel. Hur som helst kommer här pseudo-kod:
# nearest power in the choosen base, or N itself if N is a power
next_pow = nearest_power(N, base)
half_pow = next_pow / base;
for num (0..next_pow-1) {
for b (0..base-1) {
x = base * (num % half_pow);
conn = x + b;
graph->add_edge(num, conn); # connect num -> conn
}
}
Kort förklaring av programmet
Programmet har en del parametrar vilka här förklaras.
N (2..64): Det är stränglängden (eller antal objekt). Kan vara mellan 2 och 64.
Base (2..4): Basen som ska användas. T.ex. för bas 2 är det binär representation (0,1). Giltiga värden är 2,3 eller 4.
Type: normal / reversed: Normal innebär att sekvensen visas normalt från vänster till höger och de binära (bas-ära) talen kodas normal (7 binärt är "0111"). Det lägsta talet börjar decimalcykeln. Reversed är då man vänster på allting: de binära (etc) koderna är omvända (7 visas som "1110") och det högsta talet i decimalcykeln visas först.
Show connections: Visar kopplingarna för den de Bruijn-graf som byggs upp.
Show sequence: Här visas de individuella representationerna.
Exempel
Här är ett exempel på på en av många möljiga sekvenser för n = 52 i basen 4:
Sequence:0001012131301132230220330300323123212013332002102331
Cycle (in decimal): 0 1 4 17 6 25 39 29 55 28 49 5 23 30 58 43 44 50 10 40 35 15 60 51 12 48 3 14 59 45 54 27 46 57 38 24 33 7 31 63 62 56 32 2 9 36 18 11 47 61 52 16
Sequence check:
000101213130113223022033030032312321201333200210233100
000 (0)
001 (1)
010 (4)
101 (17)
012 (6)
....
Begränsningar
Som ovan nämnts bygger programmet på en slumpning av cyklerna. Det kan ta en stund att slumpa fram cykler av korrekt längd i stora grafer så finns det några begränsningar för att datorn inte ska bli sönderkörd:
N: mellan 2 och 64
base: mellan 2 och 4
Om någon läsare nu (eller sedan) upplever ett starkt behov av sådana sekvenser med större längd / bas så är det bara att kontakta mig (hakank@bonetmail.com så kan vi säkert ordna något.
Vidare utveckling
Denna slumpmässiga metod fungerar om det är relativt små värden av N och bas. Men för större värden är det inte en tillgänglig metod. I stället bör en deterministisk algorim skapas.
Ett pågående projekt är också att försöka minska antalet noder i grafen så att det inte blir så många möjliga cykler att leta igenom.
Not
Jag är osäker på om ovanstående fortfarande kan kallas för en de Bruijn-sekvens när man använder denna alternativa approach.
Se även
de Bruijn sequence (den "vanliga" formen)
de Bruijn-sekvenser (portkodsproblemet)
MathWorld deBruijnSequence
COS: Information on necklaces, unlabelled necklaces, Lyndon words, De Bruijn sequences
Posted by hakank at 06:52 EM Posted to Matematik | Program
april 17, 2006
Mutt - en konfigurerbar mailklient
I mer än 10 år har jag läst merparten av privata mail med den textbaserade mailklienten Pine. I den gångna veckan bytte jag till en annan textbaserad editor: Mutt (*).
Eftersom pålitliga vänner länge har pratat väl om Mutt har jag kikat på det flera gånger tidigare. Trådning har alltid varit ett stort argument, liksom konfigurerbarheten. Men det har alltid varit för meckigt och icke prioriterat att byta till ett annat mail-läsarsystem.
Efter att ha bitit i det sura äpplet (byte av den Linux-maskin där jag läser mail och där installation av Pine tjorvade) började jag alltså lära mig Mutt från grunden. Redan efter några minuter påträffades saker som jag nu inte förstår hur jag kunde klara mig utan. T.ex. att kunna ange vilken mailbox som ska föreslås som default när man sparar ett läst mail (s.k. save-hook, baserat på information i header-fälten, se nedan); de kraftfulla sökmöjligheterna samt naturligtvis trådningen av mailen.
Här är några för mig användbara saker från min nuvarande konfigurationsfil (.muttrc) varsamt kommenterad. Även om det inte syns så motstod jag frestelsen att definiera om Mutt så det liknar Pines tangentkonfiguration. Det mesta känns logiskt.
# använd textläges-emacs som editor
set editor="emacs -nw"
# när man läser mail ser man delar av maillistningen
# man kan toggla detta via macrot på I, se nedan
set pager_index_lines=8
# togglar om man ska se maillistningen när man läser ett mail.
# de två första är "interna funktioner" (Inspiration från Roland Rosenfeld)
macro pager _TOGIL0 ':set pager_index_lines=0
macro pager _TOGIL1 ':set pager_index_lines=9
# Finns på I (versalt i)
macro pager I _TOGIL0 'toggle pager_index_lines'
# redigera .muttrc
# kan göras dels i listningen av mail och när man läser ett mail
macro pager
macro index
# laddar om .muttrc. Notera att gamla alias etc finns kvar efter omladdning.
macro index
macro pager
# gå tillbaka till "första sidan", dvs den vanliga inboxen
macro pager Q 'c !<enter>' 'till huvudsidan'
macro index Q 'c !<enter>' 'till huvudsidan'
# definieras något annorlunda i browsern (fil/folderlistningen)
macro browser Q 'q !<enter>' 'till huvudsidan'
# grepm är ett externt program som möjliggör sökning i flera foldrar samtligt.
# Kräver grepmail
# (skriv in sökkriteriet och tryck sedan Enter)
macro index
# kopia av skickade mail sparas i en sent-mail-YYYY-MM-folder
set record="=sent-mail-`date +%b-%Y`"
# Fråga inte "move read messages to mbox" när vid avsluta
set move=no
# Fråga inte om man man ska "append to mailboxes" vid spara
set confirmappend=no
# exempel på några save-hooks: När man sparar ett läst mail kommer en speciell
# mailfolder som förslag. (För att spara mail till mailfoldrar utan att läsa dem används
# lämpligen t.ex. procmail.)
# Förklaring:
# ~f: From-fältet, ~t: TO, ~c: CC, ~h finns i någon header
#
save-hook "~t CRYPTO-GRAM-LIST@LISTSERV.MODWEST.COM" =crypto-gram
save-hook "~f comdig@ms68.hinet.net" =complexity_digest
save-hook "~h noreply-orkut@google.com" =orkut
# sorteringsordning baserad på den folder man är i
# trådning är default
folder-hook . set sort=threads
# men i spam-foldern sorteras i datumordning, senaste mailet först
folder-hook caughtspam set sort=-reverse_date
# folderlistan sorteras om omvänd datumordning
set sort_browser=reverse-date
# default vid q (quit) är No i stället för det fabriksinställda Yes
set quit=ask-no
# piper när nya meddelanden kommer i mailboxes (se nedan)
set beep_new=yes
# Förutom inkommande-foldern definieras även dessa foldrar som mailfoldrar när nya mail
# kommer in automatiskt t.ex. via procmail
# Det innebär att det piper när det kommer nya mail , de hanteras speciellt
# i folderlistan, att man via kommandot "." (punkt) ser om det kommit nya mail etc
# Not: det är anonymiserade foldernamn.
mailboxes =folder1 =folder2 =folder3
En sak störde mig stort från början och det var att Ctrl-C (för att avbryta en operation) alltid frågade om man vill avsluta Mutt och default var att det ville jag. Men det ville inte jag; jag ville inte ens ha frågan. Tyvärr hittades inget konfigurationskommando för att styra detta beteende, varpå frågan sonika kommenterades bort i källkoden (funktionen mutt_query_exit i i curs_lib.c). Nu händer alltså inget mer än att operationen avbryts, vilket är den intuition jag har kring hur Ctrl-C ska fungera i detta sammanhang.
(*) Ja, jag läser hellre privata mail i en textbaserade mailklient än på andra sätt. Gmail är trevlig liksom Evolution, men inte tillräckligt trevliga. Det finns för- och nackdelar med respektive lösningar.
Se även
MuttWiki
comp.mail.mutt.
Tips: Via "Prenumerera på den här gruppen" och sedan "Sammandragsmail (hela meddelanden) " blir man mailad nya inlägg i gruppen cirka en gång per dag.
Yahoo! mutt-users
Manualen till version 1.5.11
Utvecklingsversionen (CVS).
Exempel på konfigurationsfiler (från Wikin)
dotfiles.com har fler exempel på konfigurationsfiler.
mutt next generation, en variant av Mutt med extra features. (Att kika mer på.)
procmail för att automatiskt filtrera mail till mailboxar. Kombineras lämpligen med ett spamupptäckarprogram, t.ex. Spamassassin.
Posted by hakank at 08:17 FM Posted to Program | Comments (1)
februari 13, 2006
Svenska synonymvägar
Gårdagens Svenska synonymer och begreppet "surfa synonymer" inspirerade till ett annat program: Svenska synonymvägar.
Programmet utgår från ett ord och dess synonymer (om sådana finns) och visar deras synonymer, och sedan deras synonymer osv. Man kan notera att ofta försvinner orginalordets betydelse snabbt så och det blir helt andra spår att vandra. Därav namnet synonymvägar.
Exempel
Ett väldigt litet exempel är synonymvägen för fågel som endast innehåller 5 ord. Det ser ut så här:
fågel
fjäderfä
flygfä
pippi
höns
Synonymerna länkas alltså, vilket gör att man kan klicka runt så att man bli alldeles snurrig i huvudet....
Som sagt, detta var ett litet exempel med endast 5 ord i synonymvägen. Det finns betydligt större vägar, t.ex. för ordet känslig där vägen har 6682 ord. OBS: Det tar en stund för programmet att lista ut vägen, och sedan för webbläsaren att rendera sidan (som är på över 1 Mb).
Not
Synonymlistan är exakt samma som används i programmet Svenska synonymer, och som presenterades i blogganteckningen Svenska synonymer.
En not av mer teknisk natur är att jag hellre skulle vilja visa detta som en graf med bågar och noder för att visa kopplingarna (synonymer) mellan orden.
Eventuell vidare utveckling
Förutom att presentera det som en synonymgraf vore det intressant att se hur lång den största vägen är, hur många "isolerade synonymöar" det finns (där endast ett fåtal ord sammanbinds med varandra men inga andra), och överhuvudtaget analysera mer med grafteoretiska eller komplexa nätverkstekniker. Det bli eventuellt ett senare projekt.
Se även
Blogganteckningen Svenska synonymer
Programmet Svenska synonymer
För vidare utveckling och analys kan möjligen litteratur och redskap som presenteras i Social Network Analysis och Complex Networks - En liten introduktion vara av intresse.
Uppdatering 1 - angående synonymkluster
Det skapades ett analysprogram för att studera de olika synonymklustren. Ett kluster innebär alltså att oavsett vilket ord man söker i klustret kommer det att visas endast dessa ord, där endast den inbördes ordningen förändras beroende på vilket ord man börjar på.
Intuitionen som nämndes i kommentaren till Simon nedan stämde relativt bra: Det finns ett enda mycket stort kluster ("Den Stora Vägen", "Det Gigantiska Klustret") som innehåller 6682 ord (känslig-klustret), därefter ett på 32 ord (bandit), ett på 30 (bastard) etc.
Fördelningen av klusterstorlekn är som följer. Uttolkning: det finns 1269 synonymöar (synonymgränder?) med endast 2 ord, 271 stycken kluster som innehåller endast 3 ord etc, och som nämnts ovan ett kluster med 6682 ord. Power law, någon?
Klusterstorlek: Antal kluster
2: 1269
3: 271
4: 87
5: 57
6: 34
7: 21
9: 13
8: 8
11: 5
10: 5
16: 4
12: 4
6682: 1
32: 1
30: 1
24: 1
23: 1
21: 1
20: 1
19: 1
15: 1
Filen synonym_kluster.txt innehåller samtliga kluster, enligt strukturen:
Antal ord i klustret: Orden som ingår i klustret (alfabetiskt sorterade)
Filen är sorterad alfabetiskt efter första ordet i klustret.
Kommentar: I och med att det endast finns ett mycket stort kluster är strukturen relativt stabil i meningen att om man lägger till en synonym så påverkas inte resultatet så mycket. Det är dock kvar att studera vad som händer om man tar bort en eller ett fåtal synonympar från det stora klustret. Det är möjligt att det finns ett enda synonympar som håller ihop två (mindre) kluster till detta stora. Men det tänker jag inte kolla in i kväll...
Uppdatering 2 - Kortaste synonymvägen mellan två ord
[Senare not: Det uppstod tyvärr en tankebugg vid ursprungsbefolningen av talen i listan, och som upptäcktes efter att Simon kommenterat resultatet. De tidigare och felaktiga värdena är kvar men överstrukna för att kommentarerna ska bli förståeliga; samt i ärlighetens namn.
Trots denna nesliga händelse fortsätter jag hävda att simuleringar är ett bra sätt att räkna ut mer komplicerade sannolikheter.]
Simon föreslog i sin kommentar en trevlig applikation: Kortaste synonymvägen mellan två ord.
Klusteranalysen ovan gav dock upphov till en fundering hur stor sannolikhet det är att två ord verkligen har en synonymväg. Om de två orden överhuvudtaget finns i listan (av cirka 25000 ord) krävs det även att de tillhör samma kluster, annars kan man inte skapa någon synonymväg. Om orden finns i det stora klustret (med 6682 ord) kan det vara intressant, liksom om orden finns i de andra större klustren (säg större än 10 ord). Man kan här notera att det finns hela 1787 kluster (se ovan för den exakta fördelningen).
För att räkna ut sannolikheten att två ord tillhör samma kluster (om båda orden finns i listan) gjordes en R-simulering enligt följande:
* Varje kluster representeras av ett unikt tal, och antalet ord bestämmer hur många gånger detta tal finns i en lista (kallad "kluster" i R-koden nedan). Funktionen rep(tal, antal) kan användas för att populera listan med talen.
* Ur denna stora lista av tal dras slumpmässigt två element.
* Om de två dragna talen är lika motsvarar det samma kluster, vilket alltså ger en synonymväg. Är talen olika finns ingen sådan väg
* Detta görs ett antal 1000 gånger.
R-koden för själva simuleringen (med 100000 dragningar) ser ut så här:
> sum(replicate(100000, diff(sample(kluster,2)))==0)/100000
[1] 0.02567
0.33059
Resultatet innebär att det är cirka 2.6% 33% sannolikhet att två tal (ord) tillhör samma kluster. Det är inte mycket. Det är ju inte så pjåkigt.
Ovanstående resultat förutsätter alltså att båda två orden fanns i synonymlistan, vilket troligen inte är fallet för en normal användning av ett sådant program.
Varpå nästa analys göres: Om vi nu antar att det finns en möjlighet att användaren av systemet anger något av - säg - 75000 ord som inte finns i synonymlistan, hur stor är då sannolikheten att det finns en väg mellan dessa ord.
Här fortsätter simuleringen med samma princip och lägger 75000 unika tal en enda gång, vilket motsvarar det "klusterlösa" orden som inte finns i synonymlistan.
Motsvarande simulering (med 10000 dragningar) ger vid handen att sannolikheten är väldigt liten, nämligen endast:cirka 0.00051 (0.5 promille) 0.007 (7 promille). Det är ännu mindre. Det är inte så mycket.
Trots detta nedlyftande resultat finns det möjlighet att Simons föreslagna program ser världens ljus... Trots alternativt tack vare ovanstående resultat finns det möjlighet att någon variant av Simons föreslagna program kommer att se världens ljus...
Det finns även en tanke att från en ordlista med cirka ord lägga till böjningsformer till de synonymfilens grundord. Detta skulle göra sannolikhet för att orden finns med i (den då utökade) synonymlistan större.
Tillägg till Uppdatering 2
Vid uppdateringen av föregående analys (i "Uppdatering 2") testades även med att anta att det skulle vara färre ord än 75000 som inte fanns i synonymlistan. För 25000 sådana extra ord blir sannolikheten cirka 3.3% för en synonymväg. Möjligen är både 75000 och 25000 orealistiskt många. Här nedan är sannolikheten (inte procent) för några värden av antal icke-synonymord ("extra ord").
| Antal extra ord | Sannolikhet (simulerad) att två sökord ingår i sammakluster |
| 75000 | 0.007 |
| 25000 | 0.033 |
| 10000 | 0.097 |
| 5000 | 0.161 |
| 1000 | 0.281 |
Det är troligen en uppgift för kognitiva psykologer att lista ut hur stor ens mentala ordlista är när man använder denna typ av tjänster. En möjlighet är att logga de ord som används i det eventuella framtida program och sedan göra lite analyser. Obs: ingen annan information än orden skulle i så fall loggas; inget IP-nummer, inget datum, utan endast de två potentiella synonymvägsorden..
Posted by hakank at 07:52 EM Posted to Program | Språk | Comments (7)
februari 12, 2006
Svenska synonymer
På sidan Folkets synonymlexikon Synlex - en sida under Skoldatanätet - Lexin - finns att ladda ner en XML-fil med cirka 25000 svenska synonymer (filen är ungefär 1.5Mb stor).
Synonymlistan har skapats bl.a. genom att användare av Lexin-programmen har fått skriva in egna synonymer samt bedömt hur bra synonymerna är, därefter har filteringar av materialet gjorts. Se Synlex-sidan för vidare förklaring. Nedan direktlänkas till två rapporter om projektet.
Programmet Svenska synonymer
Omedelbart efter att Synlex-sidan upptäcktes skrevs ett program för att söka i synonymlistan där en lokal kopia av preprocessad XML-filen används. Programmet heter Svenska synonymer och har följande finesser som jag saknat i andra webbaserade synonymlexikon:
- Man kan välja att söka efter delord, t.ex. om man skriver in ordet tolka hittas även synonymer till orden "feltolka", "misstolka" och "uttolka".
- Synonymerna är länkade så att man kan följa varianterna, och s.a.s. "surfa synonymer".
Talen inom parentes efter synonymerna anger medelvärdet av hur bra synonymerna ansetts vara (kallas "level" i XML-filen) . Synonymlistan innehåller endast de synonymer som har medelvärde 3.0 eller mer, med max 5.0 (så man kan se det som betyg enligt den gamla skolordningen).
Fördelningen av dessa värden är
3.0: 3394
3.1: 1936
3.2: 2076
3.3: 1800
3.4: 1336
3.5: 1511
3.6: 1282
3.7: 837
3.8: 674
3.9: 176
4.0: 3158
4.1: 1160
4.2: 1390
4.3: 1064
4.4: 646
4.5: 914
4.6: 896
4.7: 446
4.8: 424
4.9: 60
5.0: 710
Se även
På sidan Folkets synonymlexikon Synlex finns (längst ned) två referenser till hur projektet fortlöpt:
Viggo Kann: Folkets användning av Lexin en resurs (PDF)
Viggo Kann, Magnus Rosell: Free Construction of a Free Swedish Dictionary of Synonyms (PDF)
Sajten Synonymer.se använder data från Göran Walters Bonniers synonymordbok (boken finns även som bokreabok på Bokus att förhandsbeställa).
Posted by hakank at 09:13 EM Posted to Program | Språk
januari 30, 2006
Svenska ordklasser samt gissning med hjälp av ordsuffix
Programmet Visa ordklasser visar ordklasser för svenska texter. Programmet bygger helt på uppslag i en ordlista och gör ingen grammatisk analys eller något sådant avancerat. Finns flera möjliga ordklasser för ett ord visas samtliga kända.
Som exempel visas hur den första av föregående meningar analyseras av programmet:
programmet<substantiv:bestämd form singularis> visa<verb:infinitiv|verb:imperativ|adjektiv:bestämd form|adjektiv:pluralis|substantiv:obestämd form singularis|substantiv:obestämd form pluralis|substantiv:bestämd form pluralis> ordklasser<substantiv:obestämd form pluralis> visar<verb:presens|substantiv:obestämd form pluralis> ordklasser<substantiv:obestämd form pluralis> för<verb:presens|verb:imperativ|substantiv:obestämd form singularis|preposition|konjunktion|adverb> svenska<adjektiv:bestämd form|adjektiv:pluralis|substantiv:obestämd form singularis|substantiv:obestämd form singularis> texter<substantiv:obestämd form pluralis>
Ord i fetstil är de ord som analyseras. Därefter kommer en lista av kända ordklasser för detta ord inom hakar (< ... >). Finns det flera varianter avskiljes de med tecknet "|" (som här ska läsas som "eller").
Programmet bygger helt på information från Den stora svenska ordlistan (sv.speling.org, som dock verkar onåbar för tillfället). Rätt mycket efterarbete (filtering och annan skyffling å data) har gjorts för snabb access av informationen.
Gissa ordklass med hjälp av suffix
Alla svenska ord finns inte med i ordlistan (och hur skulle det kunna göra det med alla fina nya konstruktioner som ständigt skapas av alla härliga nyordkonstruktionskreativa personer). Den använda ordlistan innehåller cirka 200000 ord, inklusive böjningar och andra varianter. Okända av ordlistan ord visas som OKÄNT, och listas även sist på sidan.
Det har skapats en experimentell funktion att gissa ordklass med hjälp av ordens suffix, som slås på via valet Gissa ordklass via suffix. Det finns även möjlighet att sätta en gräns för hur stort "stöd" en suffix måste ha, dvs hur många ord som har ett visst suffix i kombination med en viss ordklass. Ju lägre värde desto fler förslag kan komma att visas; låga värden kan ge (allt för) många alternativ. Standardvärdet är 1000 som suffixstöd, men ändra det gärna för att experimentera lite.
Det största suffixstödet är 19976: suffixet s för ordklassen substantiv:bestämd form singularis, genitiv. En lista över samtliga använda suffix med minst suffixstöd 2 finns i filen suffixes1-4.txt, sorterad på suffixstöd.
Exempel på ordklassgissning
Låt oss ta orden blogg, bloggare, bloggat (som alltså inte finns i ordlistan). De visas på följande sätt när valet Gissa ordklass via suffix är påslaget och 1000 som suffixstöd:
blogg<OKÄNT|g adjektiv:positiv utrum(4278)|g substantiv:obestämd form singularis(2577)> bloggare<OKÄNT|are substantiv:obestämd form pluralis(1106)|are substantiv:obestämd form singularis(1077)|re substantiv:obestämd form pluralis(1107)|re substantiv:obestämd form singularis(1104)|e verb:preteritum(5120)|e substantiv:obestämd form singularis(2288)|e adjektiv:komparativ(1320)|e substantiv:obestämd form pluralis(1124)|e verb:perfekt particip, plural(1121)> bloggat<OKÄNT|at verb:supinum(4425)|at verb:perfekt particip, neutrum(1112)|t adjektiv:positiv neutrum(10844)|t verb:supinum(5374)|t substantiv:bestämd form singularis(4404)|t substantiv:obestämd form singularis(2686)|t verb:perfekt particip, neutrum(1684)>
Här ser vi t.ex. att första förslaget för blogg är felaktigt, däremot är det andra alternativtet korrekt (substantiv:obestämd form singularis). Siffrorna efter förslaget är suffixstödet.
Not: Gissningarna sorteras först på suffixlängd (med längsta suffixet först) och därefter antal suffixstöd. Anledningen till att längden valts som första sorteringsordning är att ett längre suffix är gissningsvis mer korrekt än ett kortare. Så är i alla fall min nuvarande experimentella teori.
Se även
Tyvärr har jag inte hittat någon bra webbsida som förklarar alla ordklasser/böjningsformer som används av programmet. sv.speling.org hade en sådan (har jag för mig), men den koms alltså inte åt nu. Förslag på sådan sida emottages gärna.
Möjligen relaterat
Något om prefixträd sorterade på lite olika sätt samt komprimering
Posted by hakank at 06:56 EM Posted to Program | Språk
januari 25, 2006
Word Meld Simple - en etyd med Ajax-tekniken
Som några andra bloggare leker jag lite med Ajax-tekniken, vilket pratas mer om nedan.
Men först något om själva programmet.
Word Meld Simple
Word Meld är ett program som försöker att skapa "kreativa" ord (helst skulle det vara "roliga", men det är lite väl förmätet) utifrån ett grundord och ord från en ordlista, genom att leta upp gemensamma prefix och suffix.
En nyss utvecklad variant är Word Meld Simple som använder en enklare strategi: Utifrån två givna ord föresöker programmet att vara kreativ genom att lista ut gemensamma prefix/suffix samt n-gram (infix). Det är alltså detta program som använder Ajax-tekniken.
Exempel
Användningsområdet för slika program är inte speciellt klart, men en tanke är att om två företag skulle gå ihop kan programmet vara till hjälp för att skapa det nya företagsnamnet. T.ex. om google och Microsoft skulle slå ihop sina påsar (hädiska tanke!) föreslår programmet två kombinationer:
gooft
microsogle
varav det ena förslaget (det andra) ju inte låter så dåligt.
Andra tankar är att man tycker att en kombination av två ord är för lång och man vill slå ihop dem till ett enda. T.ex. statistiskt och signifikant:
signifikatistiskt
signifikt
signifiskt
stant
statistikant
statistisignifikant
statistiskant
Nå, det kanske inte blir så mycket enklare, men det är i alla fall ett ord.
En ytterligare användning är - naturligtvis - att skapa "vitsordet" för en ordvits.
Här är några fler kombinationer, mer eller mindre slumpmässigt tagna ur luften. Visst urval har gjorts av de av programmet presenterade ordkombinationerna.
firefox + unix:
unirefox
doktor + ordinera (som Henrik Sundström har en skoj liten tävling kring):
doktordinera
socialdemokraterna + moderaterna:
mokraterna
modemokraterna
socialderaterna
socialdemoderaterna
randomisera + kjellerstrand
kjellerstrandomisera
Ajax
Programmet är alltså skrivet med Ajax-tekniken, så några ord om detta kanske kan vara på sin plats. Möjligen är det inte det bästa exemplet, men good enough är också bra.
Vanliga CGI-program (som jag ofta använder för mina privata program) laddar om sidan för varje gång man kör programmet och man måste skyffla en massa information varje gång. Ajax använder en annan metodik och hämtar data (t.ex. kör nödvändiga program) i bakgrunden, s.a.s sömlöst. Detta gör att man kan behålla information från sidan utan att skicka med en massa parametrar (vilket tenderar att bli ett härke och är helt enkelt trist). Bibehållandet av datan på samma sida symboliseras med räknaren av antalet sökningar, en JavaScript-variabel som uppdateras varje gång.
För att göra programmeringen lite enklare har här används Perls modul CGI::Ajax (f.d. perljax), men det är inte speciellt svårt att rulla en egen-variant för ett så simpelt program som detta (enkelt vad gäller data som ska skyfflas via webben, alltså) . Uppdatering: jag fixade ett av problemen genom att skriva en egen variant.
Notera att något är lurt i vissa webbläsare vad gäller den nationella tecknena (t.ex. "å", "'ä" och "ö").
Se även
Andra "useless" program av liknande slag.
Ajax Patterns, med Ajax-ramverk i olika programspråk
googlering på "ajax programming vilket ger en massa träffar.
Uppdatering
Förutom problemet med de nationella tecknen har det rapporterats om att för vissa webbläsare "hänger det sig" när man skrivit in första ordet. Kollar på detta och återkommer...
Uppdatering 2 - återkomsten
Nu får i alla fall inte jag några problem med de nationella tecknen. Åtgärden var att i stället för att använda CGI::Ajax så skrev en egen variant av JavaScriptet istället för det färdiggenererade av Perl-modulen. Programmet nås nu på en något annorlunda adress än tidigare: Word Meld Simple.
Posted by hakank at 09:05 EM Posted to Program | Språk | Systemutveckling
januari 23, 2006
Något om prefixträd sorterade på lite olika sätt samt komprimering
Av en privat (och personlig) orsak behövdes ett program för att skapa unika prefix av ord i en lista, och sedan att presentera dessa prefix som ett träd. Anledningen var ungefär att korta ner en lista av ord till kortare ord (dess prefix).
Ett exempel på ett sådant prefixträd är för de svenska månadsnamnen:
a:
ap: april
au: augusti
d: december
f: februari
j:
ja: januari
ju:
jul: juli
jun: juni
m:
ma:
maj: maj (!!!)
mar: mars
n: november
o: oktober
s: september
Här ser vi t.ex. att månadsnamnen december, februari och november kan komprimeras till en enda bokstav, medan april och augusti båda börjar på bokstaven a så vi måste här ta till en extra bokstav för att skilja dem åt. Man kan också notera att maj inte blev något prefix alls, utan här behövs hela ordet eftersom mars, den rackaren, ligger och stör. Sådana fall markeras med !!!!
Program Prefix Trees
Det har naturligtvis skapats ett program för att kunna leka vidare med sådana här ord-listor, och som - möjligen något missledande - kallas för Prefix trees.
Programkörningen för ovanstående svenska månadsnamen finns ungefär här.
Komprimering och annat skoj
Även om det primära syftet med programmet var att skapa unika prefix och prefixträd så var det svårt att låta bli att studera vissa saker i mer detalj.
Om man kör programmet för de svenska månadsnamnet kommer det, förutom det fina prefixträdet, även lite statistik (längst ner på sidan):
...
Original total length of words: 74
Total length of prefixes: 23
Mean prefix length: 1.92
Compression factor (original length/prefix length): 3.217
Man kan bl.a. se att det medellängden av de skapade prefixen är 1.92, vilket ska jämföras med medellängden av de ursprungliga orden på 6.17. Komprimeringsfaktorn är 3.217, vilket räknas ut med formeln
(sammanlagda längden av original orden) / (sammanlagda längden av prefixerna)
Dvs: genom att använda de unika prefixen istället för de hela orden sparar man en hel del, t.ex. träd (sic!) om man skulle använda papper för att skriva dem. Det kanske blir svårt att läsa det, men man skulle kunna spara både tid och pengar på detta. Nedan kommer vi att studera hur man kan spara något mer tid/papper/pengar men i gengäld blir det i stort sett oläsbart...
Frekvenssortering av bokstäver
En finess med programmet är att man kan studera lite olika varianter av representation av orden innan det skapas prefix. T.ex.
- bokstäverna i ordet sorteras innan man gör prefixen, valet Sort (plain)
- bokstäverna i ordet sorteras i omvänd ordning, valet Reverse. Not: om man både sorterar och reverse, blir det i omvänd sorteringsordning, dvs "ö" kommer före "ä" etc.
Sedan den mest intressanta varianten: bokstavsfrekvenssortering (valet Sort by letter frequency, som innebär att innan man skapar prefixen sorterar man ordets bokstäver i ordning av hur vanliga/sällsynta bokstäverna är bland samtliga ords bokstäver. T.ex. så är det troligt att bokstaven "z" är sällsynt vilket gör att ett ord med "z" kommer att prefixas som z + eventuellt någon annan bokstav.
Om vi fortsätter med månadsnamnsexemplet får man med bokstavsfrekvenssortering följande prefixträd:
d: december
f: februari
g: augusti
j: maj
k: oktober
l: juli
n:
nj:
nju:
njui: juni
njuia: januari
p:
pl: april
ps: september
s: mars
v: november
....
Original total length of words: 74
Total length of prefixes: 21
Mean original length: 6.17
Mean prefix length: 1.75
Compression factor (original length/prefix length): 3.524
Om man jämför med det "vanliga" prefixträdet så är komprimeringsfaktorn något lägre för bokstavsfrekvenssorteringsvarianten (3.524 jämfört med 3.217).
Denna skillnad tenderar att vara beständigt: Detta innebär att om man använder bokstavsfrekvenser istället blir det något bättre komprimering. Nackdelen är naturligtvis att "förkortningen" (prefixet) är fullständigt obegriplig. Se även en mer systematisk genomgång nedan.
Några noter kring detta
Möjligen skulle man här kunna göra en analogi med Huffman-kodning (ref till en.wikiedia) som skapar binära koder efter bokstävernas frekvens, där den kortaste koden tilldeleas den vanligaste bokstaven etc.
En mer avancerad variant av prefixträd skulle vara att analysera prefixträdet för att komprimera det ännu mer.
Det går naturligtvis också att göra det väldigt enkelt för sig och koda varje ord till ett eller flera fullständigt slumpmässiga tecken alltefter ordens/bokstävernas frekvens i texten. Men det är en övning som lämnas åt vidare öden (eller övning åt läsaren/skribenten).
Den ursprungliga poängen med prefixträden var att de skulle vara lätta att skapa och (relativt) lätt att uttyda när man ser dem. När man använder sorteringar av olika slag förloras detta syfte bort i skymningen varvid endast nästa dags solstrålar är glada att se det.
Liten undersökning
Det gjordes också en undersökning hur antalet olika ord i listan påverkar komprimeringsfaktorn respektive medelprefixlängden. Detta gjordes för ett olika antal slupmässiga svenska ord (ur en ordlista på nästan 400000 ord).
Det visar sig - inte speciellt förvånande - att ju fler slumpmässiga ord listan innehåller, desto sämre blir komprimeringsfaktorn och desto längre blir medellängden på prefixen. Som variansen visar är det relativt stabila värden förutom för den första körningen (10 ord i listan). Av tidsskäl kördes endast 10 gånger med samma liststorlek.
Prefix utan någon bokstavssortering
| Antal ord | Komprimeringsgrad | Komprimeringsgrad varians | Prefix medellängd | Prefix medellängd, varians |
| 10 | 7.80730 | 4.67526 | 1.47000 | 0.12456 |
| 100 | 4.14080 | 0.02874 | 2.63700 | 0.00842 |
| 200 | 3.54860 | 0.03530 | 3.11500 | 0.01812 |
| 500 | 3.04260 | 0.00201 | 3.60800 | 0.00775 |
| 1000 | 2.70590 | 0.00199 | 4.10200 | 0.00368 |
| 2000 | 2.39940 | 0.00078 | 4.60200 | 0.00717 |
| 3000 | 2.23620 | 0.00063 | 4.96000 | 0.00207 |
| 5000 | 2.06810 | 0.00030 | 5.36400 | 0.00158 |
| 10000 | 1.84500 | 0.00009 | 5.99800 | 0.00057 |
| 20000 | 1.65400 | 0.00002 | 6.68800 | 0.00040 |
| 50000 | 1.44040 | 0.00001 | 7.68000 | 0.00031 |
| 100000 | 1.31520 | 0.00000 | 8.41300 | 0.00020 |
Prefix med frekvensbokstavssortering
| Antal ord | Komprimeringsgrad | Komprimeringsgrad varians | Prefix medellängd | Prefix medellängd, varians |
| 10 | 9.68830 | 4.15306 | 1.15000 | 0.02500 |
| 100 | 4.24470 | 0.02675 | 2.56800 | 0.01280 |
| 200 | 3.81910 | 0.02128 | 2.94800 | 0.00544 |
| 500 | 3.26520 | 0.00193 | 3.40900 | 0.00283 |
| 1000 | 2.89340 | 0.00351 | 3.83500 | 0.00372 |
| 2000 | 2.61810 | 0.00032 | 4.24200 | 0.00044 |
| 3000 | 2.47130 | 0.00082 | 4.48900 | 0.00159 |
| 5000 | 2.28780 | 0.00018 | 4.82100 | 0.00054 |
| 10000 | 2.06480 | 0.00009 | 5.36200 | 0.00042 |
| 20000 | 1.87310 | 0.00003 | 5.91000 | 0.00018 |
| 50000 | 1.65010 | 0.00001 | 6.70800 | 0.00008 |
| 100000 | 1.50710 | 0.00000 | 7.34400 | 0.00014 |
Andra exempel
Jag har även kört programmet på några andra exempel, t.ex. 1000 vanligaste svenska orden, svenska förnamnen samt svenska efternamnen (plus "Kjellerstrand") från Språkbanken:
- 1000 vanligaste svenska orden (inklusive siffror, årtal och delar av förkortningar)
- 1000 vanligaste svenska orden, sorterade enligt bokstavsfrekvens
- 1000 vanligaste svenska förnamnen
- 1000 vanligaste förnamnen, sorterade enligt bokstavsfrekvens
- 1000 vanligaste svenska efternamnen (plus "kjellerstrand")
- 1000 vanligaste svenska efternamnen, sorterade enligt bokstavsfrekvens (plus "kjellerstrand")
- 1000 slumpmässiga svenska ord.
- 500 slumpade svenska ord, utan sortering samt med bokstavsfrekvenssortering.
Se även
En möjlig variant att göra en komprimering eller på annat sätt förkorta saker och ting är att använda reguljära uttryck, t.ex. som i programmet MakeRegex,.
Posted by hakank at 10:51 EM Posted to Program | Språk | Statistik/data-analys | Comments (2)
november 04, 2005
Sesemans matematiska klosterproblem samt lite Constraint Logic Programming
Bengt O. Karlsson ställde igår en matematisk gåta: Ett aritmetiskt problem av Hans Jacob Seseman. Se även den omslutande anteckningen Sesemania (som avslutas med en personlig anmaning). [Uppdatering: Titeln på den nyss angivna anteckningen är felaktig och ska vara Sesemana, men felskrivningen upplevdes av Bengt som en nära-Freud-upplevelse. Och hur kan man underlåta att ge Bengt en sådan njutning? Därför står felstavningen kvar i sin ursprungliga - men alltså felaktiga - prakt. Se något mer i kommentarerna till Bengts Sesemana -artikel. I sanningens namn korrigerades först felet, men sedan korrigerades rättet och denna uppdatering skrev som ett förtydligande.]
Det var ett kul litet problem, och inte speciellt svårt att lösa. En av utmaningarna var att korrekt tolka gammelsvenskan för att förstå vad problemet egentligen bestod av. Försök gärna lösa problemet själv innan ni läser vidare eller läser kommentarerna till problemet.
Uppdatering 2
På begäran har programmet Seseman's Convent Problem (se nedan) nu även möjlighet att visa unika lösningar, eller - mer korrekt - samla lösningar som är lika vad gäller rotation, spegling etc. Denna unicifiering har gjorts i CGI-programmet, ursprungligen som ett analysstöd för att eventuellt senare göra sådant i CLP-programmet.
Problemet
Problemet består av 4 liknande delproblem där det gäller att givet ett visst antal personer i ett kloster (nunnor samt eventuellt "tillkomne Karlar") ska man placera ut dessa personer i rum så att vissa villkor uppfylls.
A, B, C, D, E, F, G, H betecknar klostrets olika rum. Rummet "_" används inte, forutom att presentera en fin kvadrat.
A B C
D _ E
F G H
Ett krav är att vissa rader/kolumner ska ha summan 9:
A + B + C = 9
A + D + F = 9
C + E + H = 9
F + G + H = 9
Ett annat krav är att totalantalet personer ska vara en av de fyra summorna (24, 28,20, 32), som man själv fick lista ut med lite enkelt aritmetik. Villkoret är alltså:
A + B+ C + D + E + F + G + H = Totalsumma
Notera att det inte står någonting om huruvida rum kan vara tomma eller ej (se nedan om detta).
I kommentarerna till problemet visades ett antal olika lösningar, och det visar sig att problemet inte är entydigt eftersom några delproblem har flera lösningar, varav några presenteras av Fredriik och Hakke (också en Håkan K) samt undertecknad (Håkan K).
Constraint Logic Programming
Men det finns fler lösningar än så.
Problemet löstes ursprungligen med penna och baksidan av ett papper, men efteråt skapades ett litet CLP-program (Constraint Logic Programming) för att generera de olika lösningarna, närmare bestämt i det Prolog-baserade programspråket ECLiPSe (Gratis att ladda ner, men man måste anhålla om en licens.)
ECLiPSe-programmet finns här. Den centrala funktionen i programmet innehåller i stort sett endast de matemaitksa uttrycken ovan.
seseman(Rowsum, Total, FirstNum, LD) :-
LD = [A,B,C,D,E,F,G,H], % deklarera variablerna
% FirstNum = 0: empty rooms allowed
% FirstNum = 1: empty rooms not allowed
LD :: [FirstNum..9],
% Radsumma/Kolumnsumma
A+B+C #= Rowsum,
A+D+F #= Rowsum,
C+E+H #= Rowsum,
F+G+H #= Rowsum,
% summan av alla tal = Total
A+B+C+D+E+F+G+H #= Total,
labeling(LD).
Den magiska genereringen av giltiga lösningar enligt restriktionerna (constraints) hanteras av labeling.
För att köra programmet från kommandoraden anger man följande:
eclipse -b seseman.ecl 9 24 1 -e 'go.'
där 9 är radsumman, 24 totalsumman. Talet 1 är ett hack för att ange att inget rum får vara tomt (0 om rum får vara tomma). -e 'go' är anropet till funktionen go och -b anger filnamnet.
Lösningar och ett webb-program
Det skrevs även ett webb-program som kommunicerar med ECLiPSe-programmet: Seseman's Convent Problem (monastary är munkkloster, convent är nunnekloster). Detta program gör det också möjligt att ändra på parametrarna skulle man så önska leka lite.
T.ex. finns det 7 lösningar för totalsumma 20 om man inte tillåter tomma rum och hela 73 lösningar om tomma rum tillåts.
Notera att programmet inte tar hänsyn att två lösningar kan vara samma fast de är roterade, spegelvända etc. Uppdatering Jodå, det gör det nu.
För de fyra olika totalsummorna som angav i problemet förevisas här antalet lösningar och om rum får vara tomma eller ej:
24 personer, tomma rum tillåts ej: 85 lösningar
24 personer, tomma rum tillåts: 231 lösningar
Som problemet är formulerat finns det dock bara en korrekt lösning för första delproblemet (24 nunnor): samtliga rum innehåller vardera 3 nunnor.
28 personer, tomma rum tillåts ej: 35 lösningar
28 personer, tomma rum tillåts: 165 lösningar
20 personer, tomma rum tillåts ej: 7 lösningar
20 personer, tomma rum tillåts: 73 lösningar
32 personer, tomma rum tillåts ej: 1 lösning
32 personer, tomma rum tillåts: 35 lösningar
Programmet har dock kvar begränsningen att maximalt antal personer som får finnas i ett rum är 9. Vi kan väl säga att det beror på att jag vill vara snäll mot webbservern. Om man vill leka med större värden kan man ändra 9 till något annat (t.ex. Total) på denna rad:
LD :: [FirstNum..9],
Kommentarer
Jag har inte hittat någon ren matematisk lösning på problemet, men en sådan kanske kommer (av någon). Ovanstående program gör det i alla fall möjligt att empiriskt studera problemet. Uppdatering: Det finns en bok Sesemans problem som kanske innehålla slika lösningar.
Man kan möjligen misstänka att Fredrik nu kommer att skriva ett mycket elegantare Python-program för detta problem.
För den som vill läsa mer om Constraint Logic Programming kan rekommenderas Programming with Constraints av Kim Marriott och Peter Stuckey. Boken innehåller många exempel som finns att ladda ner.
Posted by hakank at 11:48 EM Posted to Constraint Programming | Matematik | Program | Comments (12)
september 11, 2005
Ordavstånd (edit distances): Levenshtein och Hirschberg med lite extra finesser
Sedan länge har jag varit intresserad av hur lika ord är varandra. Ett sätt är att se hur många operationer som krävs för att transformera det ena ordet till det andra, och på detta vis få "ordavståendet" mellan orden. Se nedan för lite andra skriverier och program i detta och näraliggande ämnen.
Exempel
Ordavståndet mellan ordet håkan och ordet hakank är 2 eftersom det krävs två operationer för att transformera det första ordet till det andra: byt ut "å" till "a" och lägg till ett "k" på slutet. De möjliga operationerna för att omvandla ett ord till ett annat är:
* byt ut (replace)
* lägg till (insert)
* ta bort (delete)
samt "behåll" (keep) som egentligen inte är en operation eftersom ingenting görs. De engelska begreppen används nedan.
Edit distances
Sådana transformationer/jämförelser kallas för (används i) edit distance (googlesökning). En av de mer moderna användningarna är att jämföra två DNA-sekvenser med varandra för att se hur mycket eller på vilket sätt de matchar eller inte matchar, och det ligger mycket forskning (och pengar!) kring att göra ruskigt snabba och bra strängjämförelsemetoder.
Två av de mest kända algoritmerna för sådant är Levenshtein och Hirschberg (namnen från respektive upphovsperson).
Programmet Edit distances
Var lugn, jag tänker inte förklara algoritmerna här. Däremot vore det skoj att visa hur de fungerar och hur de kommer fram till ordavståndet. Detta är gjort i programmet Edit distances, som nu kommer att förklaras lite mer.
Körning av programmet
Låt oss jämföra orden håkan och hakank som nämndes ovan. En körning av programmet ger följande resultat:
...
Operations (graphical):
håkan-
| |||
hakank
Explanation:
'-': insert or delete
'|': keep
' ': replace
Long description (string position in parenthesis):
keep 'h' (1)
replace 'å' with 'a' (2)
keep 'k' (3)
keep 'a' (4)
keep 'n' (5)
insert 'k' (6)
Short description (k: keep, i: insert, d: delete, r: replace):
krkkki
It was 2 edit operations:
keep: 4
replace: 1
insert: 1
('keep' is not counted as an operation)
Förklaring
Här förklaras resultatet mer i detalj. Först visas den grafiska representationen av tranformationen:
håkan-
| |||
hakank
Ett "-" i den första raden betyder att en bokstav läggs till ("insert") i det andra ordet, dvs det avslutande "k". Tecknet "|" innebär att bokstäverna är samma (operationen "keep") i samma position. Om det är tomt i mellanraden innebär det att man byter ut en bokstav (här att "å" ersätts av "a"). Ett "-" i sista raden innebär att man tar bort en bokstav ("delete").
Efter det visas en "pratversion" av operationerna i korrekt ordning, där talen inom parentes anger radpositionen (eller "operationsnumret" om man så vill). Notera att positionen inte är för orden utan för den sträng som visas i den grafiska representationen.
keep 'h' (1)
replace 'å' with 'a' (2)
keep 'k' (3)
keep 'a' (4)
keep 'n' (5)
insert 'k' (6)
Så kommer en kortversion av operationern med koderna: k: keep, i: insert, d: delete, r: replace:
krkkki
vilket helt enkelt är första bokstäverna i de engelska namnen för operationerna.
Slutligen visas lite statistik där 2:an är det eftersöka ordavståndet. Och som sagt är keep inte någon egentlig operation, så 2 kommer här från antal replace och antal insert (1+1=2).
It was 2 edit operations:
keep: 4
replace: 1
insert: 1
Två algoritmer?
Varför två algoritmer, de ger ju samma resultat? Skoj att du noterat det. Visst, de ger ofta samma resultat, men inte riktigt alltid. T.ex. för jämförelsen mellan " abc e" och "abdec" (notera mellanslagen) så ger Hirschberg följande operationer: dddkkddrki:
abc e-
|| |
---ab--dec
medan Levenshtein ger dddkkdrrr, dvs:
abc e
||
---ab-dec
De ger olika antal keep-operationer (3 respektive 2), vilket kan vara viktigt. Det är dock samma antal edit distance operationer.
Om man vill man se den exakta skillnaden mellan dessa två operationslistor passar det ju bra att använda programmet för detta.
Tips: Lägg till mellanslag före eller efter
För vissa jämförelser kan det bli väldigt tråkiga operationer, t.ex. kjellerstrand -> hakank.blogg är det i stort sett bara utbyten: drrrrrrrrrrrr. Om man däremot lägger till lite mellanslag före eller efter endera ordet kan man se lite andra mappningar.
Exempel: lägg till ett gäng (t.ex. 13 mellanslag) före "kjellerstrand" så kommer följande mappning.
kjellerstrand
| |
---------------------hakank-.bl-----ogg
Naturligtvis innebär detta att antal operationer inte stämmer med ursprungsjämförelsen, men det är kanske av underordnad betydelse. I och för sig skulle programmet kunna justera för sådant trixande, men det finns alltid risker med sådan intelligens...
Fet credit
En stor fet credit måste göras till Lloyd Allison som kodat Javascript-versionerna av Levenshtein och Hirschberg.
Mitt program använder inte koden rakt av, men den är mer eller mindre strikt konverterad till Perl-kod. Programmet har även vissa finesser som saknas på Allisons sidor, t.ex. prat- och kortversionen av operationerna. Jag har inte brytt mig om att visa riktigt alla Allisons finesser, dvs tracen för Hirschberg.
Se även liknande program och skriverier
Skapa stavfel som råkar använda samma operationer som i ovan nämnda program. Där finns även några andra referernser.
Läsning av förvanskade ord
Nearest words
New Markov words II
Eventuellt relevant är också kategorin: Reguljära uttryck etc.
Lite länkar
Dan Hirschberg, speciellt dennes publikationer
Dan Gusfield: Algorithms on Strings, Trees, and Sequences
Alberto Apostolico, Zvi Galil (ed): Pattern Matching Algorithms.
(Det var det. Nu kan jag fundera lite på Thebes Visualiserad singulärvärdesuppdelning.)
Posted by hakank at 10:14 EM Posted to Program | Reguljära uttryck etc | Språk | Comments (4)
augusti 27, 2005
base_conv: Konvertering av ord till tal till ord
Som hjälp för Mats Anderssons födelsedagsgratulationshälsningshuvudbry samt ledtråd till en av gåtorna i Augusti-pyssel publiceras nu ett litet program: base_conv: Yet another word to number to word conversion.
Principen är enkel: Man utgår endera från ett "ord" eller från ett decimaltal varpå programmet konverterar till ett decimaltal respektive "ord" för så många baser som möjligt, från bas 2 till bas 68.
Exempel
T.ex. konverteras "ordet" blogg till decimaltalet 4640416 om blogg ses i bas 25. Bas 25 är för övrigt den minsta basen som kan representera detta "ord" eftersom "o" kräver åtminstone denna bas.
På samma sätt converteras "ordet" Håkan Kjellerstrand (utan mellanslag) i bas 68.till decimaltalet 661332330234565441547965347086985. Äsch, ni kan se hela listan här.
Språk, giltiga tecken
Det finns val för två olika språk med lite olika teckenuppsättning:
* engelska: 0..9 a-z A-Z
* svenska: 0..9 a-zåäö A-ZÅÄÖ
VI kan här se att både de små bokstäverna finns representerade och är väldigt olika. T.ex. "ordet" "åtgärdsförslag" (bas 45: 113728508327740105458241) är inte samma som "ÅTGÅRDSFÖRSLAG" som faktiskt inte ens går att representera i bas 45, eftersom "Ö" kräver bas 68, men det motsvarar decimaltalet 43778068670461409051480041 (sett i bas 68).
Ord, förresten
Konverteringen från decimaltal till "ord" skapar sällan ett "ord" utan är nästan alltid och för de högre baserna en blandning av siffror och bokstäver (förutom då man använder ett tal som konverterats från ett "ord", vill säga), och än mer sällan ett korrekt ord i respektive språk.
Mellanslag och andra lustiga tecken
Programmet tillåter alltså bara ovanstående tecken. Om andra tecken finns i ordet kommer ett felmeddelande. Mellanslag tas dock sonika bort.
En undring
Genom denna typ av konvertering kanske dubbeltydligheten i "tal" fått en praktisk mening. Möjligen kommer "riksdagstal" och 2672678331353573021 (bas 50) att användas omvartannat i framtiden?
Eventuell framtida utveckling
Jag har en liten idé om att göra någon form av "ordfaktorisering", med ungefär följande idéräcka:
* ett ord konverteras till decimaltal (för någon bas)
* decimalet faktoriseras
* faktorerna konvereras tillbaka till "ord" (i någon bas)
* om ett sådant "ord" finns i en ordlista ... vore det skoj.
Ta t.ex. "riksdagstal" (bas 50) = 2672678331353573021. Decimaltalets faktorer är:
174696276315679 samt 15299.
Visst skulle det vara lite skoj om "qqaicähbA" (bas 40 = 174696276315679) vore ett ord i svenskan. 15299 motsvarar en del kortare "ord": t.ex. "obo" (bas 25), "mgb" (bas 26), "kqh" (bas 27), "jeb" (bas 28).
Får se om det blir något med detta.
Programspråk
Programspråket som används för denna utilitet är Ruby (speciellt skoj när man vill rota i klasserna Integer och String.)
Posted by hakank at 10:32 FM Posted to Matematik | Program | Språk
juni 04, 2005
Uppdatering 2 av Devil's Word
Efter inspiration av en skoj diskussion hos Henrik Sundström har programmet Devil'S Word utökats till att även räkna med vanliga heltalssekvenser och inte bara ASCII-tecken. Välj "Use plain integers" och välj minsta respektive högsta talet i talsekvensen.
T.ex. ger följande uträkning svaret 666 för talen 1 t.o.m 51.
-1-2-3-4-5-6-7-8-9-10-11-12-13-14-15-16-17-18-19+20+21+22+23+24+25+26+27+28+29+30+31+32+33+34+35+36+37+38+39+40+41+42+43+44-45+46-47-48+49+50+51 = 666
Och om man kvadrerar talen ("Use squares": yes) finns det en kombination som ger samma måltal som resultat
-1-4-9-16-25-36-49-64-81-100-121-144-169-196-225-256-289-324-361+400+441+484+529+576+625+676+729+784+841+900+961+1024+1089+1156+1225-1296-1369-1444+1521-1600-1681-1764-1849-1936+2025-2116+2209-2304+2401+2500-2601 = 666
Mer om programmet finns rätt långt ner i Statistisk data snooping - att leta efter sammanträffanden. Bör kanske och åter påpeka att en av de poängerna med programmet är att det finns en stor chans att en mängd tal som kombinerade med matematiska operatorer (här + och -) kan de ge en viss summa (t.ex. 666). Det finns ingen som helst magi i denna typ av sammanträffanden, utan ren slump, och är en konsekvens av att man testar väldigt många kombinationer. Mer om detta finns i den ovan nämnda anteckningen.
Att jag själv tycker att det är en kul och intressant slump är en annan sak.
Se även den tidigare Uppdatering: Devil's word (sammanträffanden i ord)
Posted by hakank at 09:05 EM Posted to Program | Sammanträffanden | Comments (2)
juni 01, 2005
Consonants Away
På direkt förfrågan från en av mina besökare/användare av "useless" program kommer här en variant på Vowels Away: Consonants Away som visar de ord som är samma när man tar bort konsonanterna (och alltså endast behåller vokalerna).
Exempel: Ordet litteratur består av vokalerna "ieau". De ord som finns i ordlistan som också består endast av dessa vokaler och i samma ordning är:
* linnehandduk
* mineralull
* minnesalbum
* rikemanshus
* sidenhalsduk
* tidsmellanrum
Programmet har även en engelsk ordlista. Ordet litterature Consonant Away-liknar följande ord:
* displeasure
* literature
* literatures
Tack Carl H. för förslaget.
Kan här också passa på att rekommendera programmet Isomorphic Words som försöker att hitta "isomorfa ord". Det beskrivs mer i Isomorfa ord (Isomorphic Words).
Posted by hakank at 10:14 EM Posted to Program | Språk | Comments (14)
januari 16, 2005
Förstaversionerna av Mozilla Search Plugins för ett par "useless program"
Av någon anledning började jag för en stund sedan kika lite mer på Mozilla Search Plugins (Mycroft-projektet) till Mozilla och dess derivat såsom Firefox. Det är den där sökrutan som finns längst upp till höger (hos min Firefox i alla fall) där man kan välja vilken "sökmotor" man kan söka i.
Så jag tyckte det kunde vara roligt att skapa sådana plugin till några av mina egna program, t.ex. för några av dem som nämndes i Chiasmus-ord (omkastningar av bokstäver mellan ord).
De allra första försöken finns på hakank's Mozilla Search Plugins. Och för att göra det enkelt så listas de här nedan också. Läs gärna instruktionerna här nedan innan eget försök göres.
Egentligen ska man väl registrera dessa plugin så att de kommer med på Mycroft Download-sidan, t.ex. för att underlätta installationen av dem, men så har alltså inte gjorts.
Uppdatering: Det finns nu en länk för att installera dessa plugins.
Varningar och instruktioner
* Notera att det är ett experiment och kräver visst trixande. Men det har funkat för mig utan problem på Windows XP med Firefox version 1.0.
* Detta funkar inte för Microsoft Internet Explorer.
* Klicka på "Install"-länken
ELLER
Spara och kopiera både .SRC och .PNG-filerna från listan nedan till webbläsarens searchplugin-katalog. Det är alltså katalogen searchplugins i webbläsaren katalog.
Möjliga kataloger:
C:\Program Files\Mozilla Firefox\searchplugin (Windows)
eller ~/firefox/searchplugin/ (för Linux etc).
Man bör kopiera både SRC- och PNG-filen, men egentligen räcker det med SRC-filen. PNG-filen innehåller den bild som visas i listan. (Se sist i denna anteckning för en request.)
* Starta om webbläsaren.
Noter:
* Eftersom man bara har ett sökfält att arbeta med har det gjorts vissa default-värden, t.ex. att språk är svenska om det finns möjlighet till flera, att bara ett fält används om det finns flera etc.
* Inga garantier lämnas. Men säg gärna till om det är något konstigt, roligt eller något annat som önskas i pluginväg.
Filerna
Här är listan över programmen som "Mycroft-pluggats" samt tillhörande filer.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Så, och nu är det nog dags att kika lite mer på dokumentationen (PDF).
Uppdatering: Det har nu gjorts. Det finns en massa roliga saker att göra, faktiskt mer än vad jag först trodde. Till exempel var det väldigt enkelt att göra en installationslänk .
Request
Som ovan skrevs är det samma ikon för varje plugin, ett "h" (för "hakank"). Egentligen tycker jag det skulle vara snyggare med följande symbol: /h/ dvs slash-h-slash eller möjligen ett h, dvs ett kursivt "h". Problemet är att mina förmåger att skapa snygga ikoner är låga. Någon som har ett tips på ett bra program där man bara skriver in texten man vill ha och vips blir det en fin bild som man kan använda i ovan nämnda syfte. Det kan vara på endera Linux eller Windows-plattform.
Posted by hakank at 09:43 EM Posted to Program
januari 15, 2005
Chiasmus-ord (omkastningar av bokstäver mellan ord)
Johnny Söderberg på stationsvakt (Sonny Jöderberg på vaktionsstat) skrev i Freila om hur han tycker det är roligt att leka med ord. En sysselsättning som jag också är road av.
I kommentarerna hos Johhny nämnde jag några program som eventuellt kan hjälpa till vid sådana ordlekar. (Se nedan för den fullständiga kommentaren.)
Ett exempel som Johnny tar upp är den s.k. chiasmus-tekniken, dvs att byta ut delar av ett ord med ett annat, t.ex. att de första bokstäverna byter plats (se även nedan under "Mera om chiasmus"). Exempel:
Laila Freivalds blir Faila Lreivalds
Johnny Söderberg blir Sonny Jöderberg
Sture Pyk blir Pure Styk
Det totades därför ihop ett litet program för slika operationer på två ord där operationerna för närvarande är:
- de första 1..N bokstäverna i respektive ord byter plats
- vokalerna byter plats (först de respektive första vokalerna, sedan respektive andra vokalen etc)
- ordens respektive stavelser (rättare: allting från början av ordet till och med en stavelse) byter plats, där vokalen i stavelsen antingen inkluderas eller inte (två varianter alltså)
Programmet finns till allmänt beskådande och användande på Chiasmus words (characters). Johnny får härmed en officiell cred för inspirationen till detta program.
En exempelkörning på orden "Laila" och "Freivalds" blir som följer
Original words:
Laila Freivalds
Language: Swedish
Switching first N characters
N=1: Faila Lreivalds
N=2: Frila Laeivalds
N=3: Frela Laiivalds
N=4: Freia Lailvalds
N=5: Freiv Lailaalds
Switching vowels of order O
O=1: Leila Fraivalds
O=2: Laila Freivalds
O=3: Laila Freivalds
Switching syllables (including vowels) of order S
S=1: Freila Laivalds
S=2: Freila Laivalds
S=3: Freiva Lailalds
Switching syllables (excluding vowels) of order S
S=1: Fraila Leivalds
S=2: Freila Laivalds
S=3: Freiva Lailalds
Tips: Om man vill leka med ett enda ord, t.ex. "stationsvakt", kan man dela upp det så att första ordet blir "stations" och det andra "vakt". Det var nämligen så "vaktionsstat" i det inledande stycket tillkom. Uppdatering: En funktion för detta har nu byggts in i programmet.
Om du saknar någon operation i programmet får du gärna önska så får vi vad som kan göras, givet möjlighet, tid, lust och/eller andra nödvändiga resurser.
/Kjellan Håkerstrand a.k.a. Kåhan Strallerkjend
Uppdatering 1: 2005-01-16
Programmet har nu även följande funktioner:
* Det finns möjlighet att göra en "egen-chiasmus", dvs att byta bokstäver i ett och samma ord, t.ex. för att skapa konstruktioner såsom Kåhan Strallerkjend eller något på stationsvakt.
Välj Do single word chiasmus för detta.
* P.g.a. ovanstående tillägg som skapar en massa konstruktioner, finns det även möjlighet att slå av/på utskrifter av detaljerna för respektive konstruktion. Det är alltså valet Print all details. När man arbetar med egen-chiasmus kan det vara lämpligt att ha utskriften inaktiverad.
Ett exempel med all utskrift: Leila Freivalds.
* Det görs nu också en summering av samtliga konstruktioner som är rakt-upp-och-ned presentation utan fetstil etc. Summeringen visas allra sist på sidan. Summeringen för "Laila Freivalds"-sökningen ser ut så här.
Tips: det kan vara en idé att endast arbeta med små bokstäver i namn eftersom versalerna tenderar att störa helhetsintrycket.
Slut på uppdatering 1
Uppdatering 2: 2005-01-17
Nytt i denna version är:
* det finns möjlighet att göra en chiasmus på de resulterande ordparen (länken Chiasmus this word pair i summeringslistan). Exempel: första generationen av "johnny söderberg" är t.ex. "söde johnnyrberg". Om man nu gör en chiasmus på detta ordpar får man t.ex. "john södenyrberg" (och man får även originalparet "johnny söderberg"). Ja, så kan man hålla på tills man tröttnar eller maten blir klar.
* för en-ords-chiasmus presenteras de två resultatsträngarna ihopslagna inom parentes. För den vanliga två ords-chiasmus behövs ju ingen sådan ihopslagning.
* lite intelligens: om man skriver in två ord i första ordfältet men inget i det andra fältet, delas det automatiskt upp i två ord som läggs i respektive ordfält. Detta för att det ska bli enkelt att använda Mozilla Search pluginen för detta program som skrevs om i Förstaversionerna av Mozilla Search Plugins för ett par "useless program". Dessa plugins arbetar nämligen endast med ett sökfält. Säg till om det är för mycket intelligens, för då slår jag på en flagga för detta beteende.
Slut på uppdatering 2
Mer om chiasmus
chiasmus.com är en trevlig sajt som förklarar olika typer av chiasmus. Begreppet förklaras vidare i What is Chiasmus?. De tekniker som används i programmet kallas där Chiasmus of Letter Reversal, men se också t.ex. Phonetic Chiasmus.
Den (nästan) fullständiga kommentaren hos Johnny
Här är, som utlovats ovan, den fullständiga kommentaren på Johnnys Freila-anteckning (nästan eftersom kommentaren om att jag hade missat att det fanns en 1000-teckens begränsning i Johnnys kommentarssystem har tagits bort samt att URL:arna har länkats enligt gängse webbpraxis):
Johnny: Om du tycker om att vända på ord kanske du skulle bli road av program som gör en del av arbetet.
Ett exempel är programmet "Word Meld" som går igenom en ordlista och föröker hitta likheter till ett visst ord. Ibland blir det småroligt, oftast inte. Men det skapas en massa förslag i alla fall.
Programmet ger bl.a. följande varianter på "freivalds" (resultatet är något redigerat; inom parentes visas ordlisteordet som matchade):
* freivallmo (vallmo)
* freivalpig (valpig)
* freivaluta (valuta)
* freivaldehyd (aldehyd)
Med ditt efternamn, dvs Söderberg får man t.ex. följande:
* flöderberg (flöde)
* söderberest (berest)
* söderbergonom (ergonom)
* söderbergfast (bergfast)
Om inte annat kan de föreslagna orden vara utgångspunkt får egna övningar.
Två varianter av programmet finns:
En Javaversion samt en vanlig webbapplikation (som är långsammare).
Och om du känner för det kan du även kika på liknande program på Useless programs.
T.ex. Combograms som listar vilka ord man kan skapa från bokstäverna i ett annat ord.
. (Det var alltså detta program som användes i Mats Anderssons ordtävlingar i höstas.)
Eller Vowels Away som kollar vilka ord som är lika om man tar bort vokalerna från orden.
Orden "freivalds" och "förvildas" är alltså 'konsonantidentiska' eftersom de båda motsvarar konsonantföljden "frvlds". Jag drar dock inga större politiska slutsatser av detta.
Posted by hakank at 08:14 EM Posted to Program | Språk | Comments (3)
november 27, 2004
Spelling out words: En liten lek med ljudande ord
Vad har följande gemensamt: BCND, BTND, FMR, XMN, LRA, IDLA, QNLN, RND?
Jo, de motsvarar riktiga ord om man uttalar dem enligt hur bokstäverna läses ("ljudar dem"), nämligen beseende, beteende, efemär, eksemen, ellära, ideella, quenellen samt ärende. Läs ut "BCND" som "be-se-en-de", "LRA" som "ell-är-a", etc.
En fullständig (nåja) lista över de svenska ord som är "Spelling Out Words" ("Ljudande Ord"?) finns här.
Man kan notera att för dessa ord är även vokaler medräknande (som ju ljudas endast som en bokstav, dvs "a" => "A", "e" => "E").
Det finns också en lista över ord som inte fullständigt kan översättas men som innehåller tillräckligt många översättningar att det blir lite skoj. Vokalerna har ignorerats eftersom de inte tillför speciellt mycket.
De ord som kunde konverteras mest listas härnedan. Talet efteråt är andelen konverterade bokstäver delat med ordets totala antal bokstäver.
quenellens: QNLNs: 0.90
elementet: LMNTt: 0.89
resenären: rSNRN: 0.89
elementär: LMNtR: 0.89
beteendes: BTNDs: 0.89
begärelse: BgRLC: 0.89
elelement: LLMNt: 0.89
elementen: LMNTn: 0.89
bevekelse: BVkLC: 0.89
beteenden: BTNDn: 0.89
beteendet: BTNDt: 0.89
eksemens: XMNs: 0.88
perennen: PrNN: 0.88
esseltes: SLTs: 0.88
essensen: SNCn: 0.88
essenser: SNCr: 0.88
quenells: QNLs: 0.88
serveess: CrVS: 0.88
Några andra favoriter:
insektsätande: InCktZnD
bearbetade: BarBtaD
empedokles: MPdoklS
esteter: STTr
enkelelement: NkLLMNt
elementärkurser: LMNtRQrCr
Det gjordes också ett litet program som listar sådana översättningar. Se Spelling out words för att leka med programmet. Än så länge är det endast svenska ord som hanteras.
Översättningsreglerna är som följer (vänsterledet är de bokstäver som ersätts med högerledet):
be => B
ce => C
se => C
de => D
ef => F
eff => F
ge => G
hå => H
ji => J
kå => K
ell => L
el => L
em => M
emm => M
en => N
enn => N
pe => P
qu => Q
ku => Q
err => R
är => R
ärr => R
es => S
ess => S
te => T
dubbelve => W
ve => V
we => V
eks => X
ex => X
äx => X
zäta => Z
säta => Z
Slutligen: För andra ord/språk/etc-saker se även mina andra "useless programs".
Posted by hakank at 12:14 EM Posted to Program | Språk | Comments (5)
maj 08, 2004
Isomorfa ord (Isomorphic Words)
Mats Andersson ställde häromdagen en kryptografisk gåta Nytt krypto, som helt enkelt frågar vad F O J K Ö N W Å C W N O S Q betyder.
Efter några försök med standardsaker såsom "difford", rot13, rotN etc, funderade jag på om det kanske var ett substitutionschiffer (ersättningschiffer, substitution cipher), dvs där varje bokstav ska bytas ut mot en annan.
Eftersom sådana chiffer inte nödvändigtvis har unika lösningar, skrevs ett litet program för att kontrollera vilka och hur många ord (från en ordlista) som skulle kunna vara tänkbara kandidater.
I det följande kallar jag två ord som kan förvandlas till varandra med sådan substitution för isomorfa ord (av "iso": samma + "morf": form/struktur).
Programmet Isomorphic Words
Programmet som skapades har nu gjorts webbanpassats och finns på Isomorphic Words, där det beskrivs mer hur programmet fungerar, vad som menas med isomorfism etc.
Tillbaka till Mats pyssel
Listan med isomorfa ord till strängen FOJKÖNWÅCWNOSQ blev 984 ord lång (från en ordlista på cirka 117000 svenska ord)! Här är några av dem, kanske inte helt slumpmässigt utvalda:
- alfabetisering
- antediluviansk
- automatisering
- bakgrundsmusik
- bokstavstrogen
- bredvidläsning
- dataöverföring
- desinformation
- förväntansfull
- gemenskapsform
- glädjespridare
- gudsnådelighet
- högteknologisk
- kryptogamflora
- kuriosasamling
- meningsfullhet
- oklassificerad
- operativsystem
- outgrundlighet
- rekordslagning
- schvungfullhet
- sifferunderlag
- självalstrande
- skarpsinnighet
- snackesalighet
- textbehandling
- tolkningsmetod
- trollkunnighet
- vardagsgöromål
- vilkensomhelst
- stjärneskådare
Programmet visar även en möjlig mappning (av möjligen flera möjliga mappningar) mellan bokstäverna i orden. T.ex. för ordet stjärneskådare kan man göra följande mappning från strängen FOJKÖNWÅCWNOSQ:
- 1 char: [CÅFKJQSÖ] -> [aäkjntåd]
- 2 chars: [ONW] -> [esr]
Detta innebär att de bokstäver som förekommer exakt en gång i det inknappade ordet, dvs bokstäverna [CÅFKJQSÖ], kan ersättas med vilken bokstavs som helst som förekommer exakt en gång i stjärneskådare, dvs [aäkjntåd]. På samma sätt kan de bokstäver som förekommer två gånger i respektive ord kan bytas ut mot varandra.
Exakt isomorfism
Programmet har även möjlighet att göra en mer strikt kontroll, där inte bara antalet förekomster av respektive bokstäver ska vara samma i de två orden, utan även där bokstävernas positioner är relevanta. T.ex. orden anna, amma och esse är exakt isomorfa eftersom de har exakt samma uppbyggnad/form: Först en bokstav, sedan en annan, därefter samma bokstav som nummer 2 och till sist samma bokstav som började ordet. Ett ord som jojo är isomorft (två förekomster av respektive två bokstäver) men inte exakt isomorft eftersom det inte har den eftersökta strukturen.
För strängen FOJKÖNWÅCWNOSQ hittades ingen exakt isomorfism i den svenska ordlistan; inte heller i den engelska för den delen.
Uppdatering:
Efter att ha kollat i en betydligt större engelsk ordlista som även inkluderar fraser, hittades den exakta isomorfismen parcel of land som vad jag förstår betyder ungefär "jordlott" (som enligt NE i sin tur har "parcell" som synonym). Mappingen är:
- 1 char: "CÅFKJQSÖ" -> "cedfonpr"
- 2 chars: "ONW" -> "a' 'l"
Där hittades även en exakt isomorfism på kjellerstrand: nämligen shipping note med mappningen
- 1 char: "adkjnst" -> "' 'eghost"
- 2 chars: "elr" -> "inp"
(Slut på uppdateringen.)
Däremot har ordet Ordet andersson har följande fyra svenska exakta isomorfismer:
- lakryssja
- 1 char: "aedor" -> "kjlry"
- 2 chars: "ns" -> "as"
- 1 char: "aedor" -> "kjlry"
- professur
- 1 char: "aedor" -> "efopu"
- 2 chars: "ns" -> "sr"
- 1 char: "aedor" -> "efopu"
- trägaller
- 1 char: "aedor" -> "aeägt"
- 2 chars: "ns" -> "lr"
- 1 char: "aedor" -> "aeägt"
- undfallen
- 1 char: "aedor" -> "aedfu"
- 2 chars: "ns" -> "ln"
- 1 char: "aedor" -> "aedfu"
Själva mappningen är här något annorlunda jämfört med "vanliga" isomorfa ord, eftersom positionen spelar roll. För ordet undfallen innebär det att bokstäverna "a", "e" och "d" (från andersson) mappas till samma bokstav i undfallen, men "o" ska mappas till "f", "r" till "u", "n" till "i" samt "s" till "n".
Man kan även notera att mats andersson har 806 isomorfa ord, t.ex. visirvärdighet, trosbekännelse samt amfiteatralisk, men inga exakta isomorfa ord.
Här är några exempel på mer strukturerade former. Man kan notera det förenklade sättet att skriva ut strukturen på de eftersökta ordet.
abcdefghijklm, dvs 13-bokstavsord utan upprepning av bokstäverna,. Det finns 42 sådana i ordlistan, t.ex. vänskaplighet, fasmodulering och fetischdyrkan.
abbccdd: irreell
abbcc: reell
Palindrom:
abcba: 12 stycken, t.ex. varav, girig och kajak
abccba: tillit
Se även
Mats tidigare kryptoproblem: Kod.
Mina andra "useless" program.
Programmet är f.ö. skrivet i Python, och innehåller inte ett endaste reguljärt uttryck.
Uppdatering: OK, kryptogåtan är löstes till slut. Det var inte något substitutionschiffer. Se kommentarerna i problemlänken.
Posted by hakank at 10:04 FM Posted to Program | Språk
april 05, 2004
Uppdatering: Devil's word (sammanträffanden i ord)
Programmet Devil's word skrevs för att visa att det finns stora möjligheter att hitta rent slumpmässiga sammanträffanden genom att försöka få fram en viss summa ("djävulstalet", 666) från ett namn. En inramning av detta gjordes i Statistisk data snooping - att leta efter sammanträffanden.
Nu har det kommit en ny version av programmet. Nyheterna är
- Man kan skriva in vilket måltal som helst, dvs inte bara 666
- Något längre ord kan klaras av (cirka 30 tecken jämfört med tidigare 20)
- Avgörande av vissa matematiska omöjligheter
- Ett ord vars summa av ASCII-värden är udda kan inte kombineras (med +/-) så att det blir ett jämnt tal, och vice versa. Denna udda-/jämnhet kallas för "paritet".
- Om den maximala summan för ett ord inte når upp till måltalet är det meningslöst att giddra med talen.
I bägge dessa fall lämnas besked och eventuellt lite förslag.
Exempel 1, Exempel 2.
- Ett ord vars summa av ASCII-värden är udda kan inte kombineras (med +/-) så att det blir ett jämnt tal, och vice versa. Denna udda-/jämnhet kallas för "paritet".
- Viss statistisk information har lagts till.
- Tyvärr har det känts tvunget att lägga till en timeout i programmet (cirka 10-20 sekunder) vilket innebär att programmet inte garanterar att ge ett resultat.
Om du har något namn/ord som du alldeles förfärligt gärna vill ha kontrollerat, kontakta mig så gör jag en manuell körning (vissa begränsningar finns dock härvidlag).
En tabell över de ASCII-tecken som används i hintarna finns här.
Posted by hakank at 01:45 EM Posted to Program | Sammanträffanden | Comments (4)
december 27, 2003
Bloggidentifiering (Blog Identification)
Inpirerad av idéerna i Automatisk identifikation av språk (språkidentifiering), Automatisk bloggning? (Blog Markov) samt Markov av svenska bloggar har jag nu skapat ett program för att automatiskt identifera bloggar: Blog Identification.
Inparameter till programmet är en URL, t.ex. till en blogg. Sedan jämförs texten (se nedan) med olika bloggar, som jag synnerligen subjektivt valt ut bland några av mina dagligen besökta bloggar samt de flesta av bloggarna som finns med i Internetworld-artiklarna Världens bästa bloggar samt Bästa svenska bloggarna. (Tyvärr kommer min dator inte åt vissa bloggar, t.ex. Rymdimperiet, så jag har inte lyckats skapa en "profil" för dessa bloggar. Sorry.)
Programmet använder en n-gram metrik för att avgöra hur nära en text är de andra texterna, och använder metoden (nästan rakt av) som finns beskrivet i papret N-Gram Based Text Categorization skrivet av William B. Cavnar och John M. Trenkle. Metoden bygger på att man skapar en "profil" av de 300 mest frekventa n-grammen som sedan jämförs med en ny profil skapas från den webbsida som ska identifieras.
För att testa programmet körde jag alla bloggar som input till programmet för att se hur bra de kunde identifieras. Tanken är att en blogg ska vara sig själv närmast. Som man ser i sammanställningen lyckas det rätt bra. Idealet vore att avståndet för en sådan "självtest" är 0 (noll) men av olika skäl når man inte riktigt detta när det webbaserade programmet körs. Efterhand bloggarnas innehåll förändras kommer också resultatet att förändras, och jag vet inte riktigt hur ofta jag kommer att skapa nya profiler att jämföra med.
I slutet av sammanställningen finns en summering av placeringarna i testet. Den som fick lägst totalsumma (i körningen förmiddag 27 December 2003). Det är lite problematiskt att jämföra på detta sätt eftersom språk, ämne, HTML-layout etc påverkar resultatet. Jag vet inte riktigt vilka slutsatser man ska dra av att bajs.se har lägst totalpoäng och The church Of Me har högst.
Det finns några idéer till varianter och utvidgningar som jag nog kommer att testa inom den närmsta framtiden.
METOD
För intresserade beskrivs den metod som används, vilket i princip är en summering av ovan nämnda paper.
Skapa profil
- läs in texten
- strippa bort allt som inte är relevant. (För närvarande tar jag först bort all HTML-kod samt allt som inte är vanliga bokstäver. Detta kan ändras i framtiden.)
- skapa profilen:
- skapa en tom hashtabell
- för n=1..5:
- skapa n-grammen för n och lägg in dessa i hashtabellen
- skapa n-grammen för n och lägg in dessa i hashtabellen
- skapa en tom hashtabell
- sortera hashtabellen i frekvensordning
- spara de F (=300) mest frekventa n-grammen i frekvensordning till en fil
Så här kan en profil se ut för hakank.blogg, fast här sparas frekvensen i stället för ranknumret (eftersom ranken helt enkelt är positionen i filen). Möjligen kommer frekvensen att användas i senare versioner av distansmetrik.
Blogg identifiering
- läs in texten som ska identifieras, och skapa en profil (målprofilen)
för denna text (se ovan, men spara inte i fil)
- läs in samtliga sparade profiler
- för samtliga sparade profiler:
- jämför profilen med målprofilen m.h.a. n-gram-distans/avstånd
- spara n-gram-avståndet
- vikta avståndet (Jag har delat avståndet med 300, dvs det värde som man använder i n-gram-distans/avstånd när n-grammet G saknas i den jämförda profilen P.)
- jämför profilen med målprofilen m.h.a. n-gram-distans/avstånd
- sortera de erhållna avstånden i stigande ordning, dvs lägst avstånd (=störst likhet) först
- presentera bloggnamn etc i avståndsordning
n-gram distans/likhet
Givet: målprofil (MP) och den profil (P) som ska jämföras
- För samtliga n-gram (G) i MP:
- slå upp ranknummer (R1) för G i MP.
- slå upp ranknumret (R2) för G i P.
Om G saknas i P, tilldela R2 ett högt tal (här 300)
- räkna ut differensen mellan de två rankvärdena: abs(R1 - R2)
- slå upp ranknummer (R1) för G i MP.
- summera samtliga differenser. Detta är n-gram-avståndet mellan MP och P..
Posted by hakank at 12:11 EM Posted to Blogging | Machine learning/data mining | Program | Comments (3)
december 22, 2003
Markov av svenska bloggar
Efter Bengt O. Karlssons förslag i kommentarerna till Automatisk bloggning? (Blog Markov) har jag nu hackat ihop ett litet wrapperprogram för att markovifiera de bloggar som finns på weblogs.se:s Webbloggsindex, och är väl alla de bloggar som någonsin pingat weblogs.se?
Programmet Web Markov weblogs.se läser in ovanstående sida, mixtrar och joxar lite, samt länkar alla blogg-sidorna till Markov-programmet.
Det är inte snyggt men det är fult. :-)
Om systemansvarig på weblogs.se eller annan anser att programmet på något sätt är otillbörligt ber jag om en fin liten vink om detta.
Uppdatering
Sagde Bengt har nu en kul julgåta att knäcka där han använder texter skapade via sagda program. Se vidare Vilka bloggar är det som markoviserats så här?. Han förklarar lite mer i sin anteckning rubricerad Några nötter att knäcka daterad 2003-12-22, men bokmärkeslänken är till nämnda julnöttersida.
På en icke förekommen anledning kanske jag även bör nämna att Markov-programmen är slumpmässiga, vilket innebär att det är ganska osannolikt att exakt samma text skapas flera gånger. Jag tar inget som helst ansvar för ett eventuellt uppkommmet Markov-beroende.
Posted by hakank at 10:13 FM Posted to Blogging | Program | Språk | Comments (1)
december 21, 2003
Automatisk bloggning? (Blog Markov)
Om ni undrat hur jag skapat mina tidigare blogganteckningar kan jag nu avslöja att det gjorts med hjälp av programmet Blog Markov.
Nej, det stämmer inte riktigt.
Däremot blev jag - efter att ha skrivit anteckningen Automatisk identifikation av språk (språkidentifiering) där några Markov-generatorer nämns - lite nyfiken hur en sådan genererad text skulle bli. Jag tycker att det fångar stilen rätt bra. (Någon kommer förmodligen att säga att de inte märker någon skillnad; det bjuder jag på. :-)
Programmet använder alltså anteckningarna från min blogg med vissa filteringar.. T.ex. har allt inom < ... >-taggarna tagits bort, eftersom det ofta är text på engelska vilket stör språkligheten för mycket.
Testa gärna själv. Ändra parametern n för att ge mer eller mindre trogen text, n=10 ger mycket trogen och n=5 är ganska trogen text.
Posted by hakank at 09:21 EM Posted to Program | Comments (3)
december 05, 2003
Julklappsrim, korsord och årets julklapp
På den utomordentliga Nationalencyklopedin (NE,alltså) finns det, bland mycket annat, en rimtjänst (man måste vara registrerad användare för att använda tjänsten). Liksom deras Korsordshjälp tycker jag att det är lite knöligt att arbeta med, främst att man måste välja antal bokstäver som "målordet" ska ha ska matcha.
Om ni skulle behöva hjälp med enkla rim inför kommande julklappsrimsknepochknåpande kan jag kanske få fresta med Simple rhyme. Se t.ex. förslagen till rim på ordet blogg.
För julkorsordslösningsfunderare (och naturligtvis även åretruntkorsordsbenägna) kan jag även tipsa om programmet Cross words.
Årets julklapp
För övrigt kanske årets julklapp skulle vara en blogg istället för en mössa? När gav du din fru/man/sambo/särbo/barn/barnbarn/mor/far/morfar/mormor/farfar/farmor/syster/bror/kusin/nästkusin/nästkusins bästa grannes syster/syssling/trassling/chef/medarbetare/dig själv/eller någon annan en blogg sist?
Posted by hakank at 09:59 FM Posted to Program | Comments (5)
november 26, 2003
Upside down number words
Upside down number words är ord som när de läses upp och ned blir tal. T.ex. ordet gigolo blir talet 070616 (vänd upp och ned på skärmen för att kontrollera :-).
En liten sida tillägnad sådana ord, både svenska och engelska, finns nu på Upside down number words.
Posted by hakank at 01:05 EM Posted to Program | Comments (6)
november 13, 2003
Groovy programspråk
För några veckor sedan upptäckte jag, och började leka med, Groovy, som är ett nytt Perl/Python/Ruby-liknande programspråk.
Nu kompileras koden till Java-bytecode för att sedan användas av Java-program. Jag är osäker på om det är så det kommer att fungera i framtiden också.
Det är ännu inte färdigt, men det finns en beta (eller alfa)-version som man kan köra. Systemet var inte helt enkelt att installera, så jag skrev en (förhoppningsvis fortfarande aktuell) installationsjournal som kanske kan hjälpa något, ostrukturerad som den är. Den kan erhållas mot beskrivning.
Se även James Strachan's Radio Weblog, t.ex. Building the next new language.... Groovy? och tidigare anteckningar.
Posted by hakank at 08:10 EM Posted to Program
september 17, 2003
Skapa stavfel
Efter publicerandet av programmet Reading scrambled text häromdagen har jag fått lite reaktioner, tips och önskemål. Se min blogganteckning Läsning av förvanskade ord. (Den rapporterade buggen torde vara fixad, meddela mig annars.)
Detta program gjordes för att kolla in vilka parametrar (antal fasta tecken i början respektive slutet av ordet) som krävdes för att skapa en text som var "tillräckligt förståbar" (vad nu detta innebär).
En av de saker jag själv funderade på, och som bland annat Mats Andersson har (privat) funderat kring, är ett program som skapar mer realistiska stavfel.
Jag har inte sett något sådant program, så därför totade jag ihop ett nu i morse: Generate spelling errors.
Programmet använder tre olika operatorer för att förvanska ett ord:
- ta bort en bokstav (delete)
- lägg till en bokstav (insert)
- byt två näraliggande bokstäver (transpose)
Dessa operatorer är f.ö. i princip samma som man t.ex. använder i (Levenshteins) edit distance för att kontrollera eller söka efter snarlika ord, t.ex. just felstavningar.
Några finesser i programmet är att man kan justera sannolikheterna för dessa olika operatorer och sannolikheten att ett ord överhuvudtaget ska ändras samt hur många förändringar man ska göra per ord (om det nu ska förändras).
Jag funderade också på att även lägga in operatorn från förra programmet, men - för tillfället i alla fall - har jag lagt detta på is.
Den exakta nyttan med programmet är väl inte helt klart. En av tillämpningarna kan vara att se hur mycket vi förstår av en text efter olika typer av förvanskningar. Tyvärr kan nog spammare ha nytta av en sådan funktionalitet, vilket innebär att även spamdetektorprogramutvecklare har nytta av att skapa sådana texter.
En annan tillämpning: Om man vet man vet att det finns (slumpmässigt genererade) stavfel i en text blir man tvungen att läsa igenom texten extra noga, vilket ju är bra.
Kommentera gärna, antingen privat eller via kommentarsfunktionen.
Uppdatering
Jag hittade precis papret Detection of spelling errors in Swedish not using a word list en clair av Rickard Domeij, Joachim Hollman och Viggo Kann. Där står det (sidan 5)
Many studies ... show that four common mistakes cause 80 to 90 percent of all typing errors:
Jag har nu även implementerat den fjärde, dvs att byta ut en slumpmässig bokstav i ordet mot en annan helt slumpmässig bokstav. Detta är kanske inte helt realistiskt eftersom sådana stavfel väl tenderar att innefatta näraliggande tangenter.
(Kolla även vad de tre författarna gjort i övrigt. Mycket intressanta saker är det.)
Posted by hakank at 11:31 FM Posted to Program | Comments (5)
september 15, 2003
Läsning av förvanskade ord
Enligt en text som spridits på nätet den senaste tiden räcker det att de första X tecknen och de sista Y tecknen i ett ord ska vara i korrekt position för att vi ska kunna förstå en text. Enligt texten hos Mats Andersson är X=Y=2, och enligt texten på Kalles klätterträd är X=Y=1.
Jag tyckte det kunde vara en lite lagom avkoppling att göra ett litet snabbhack för att kolla detta llite. Så här är ett program för att slumpa de tecken som finns mellan de X första respektive Y sista tecknen i orden. X och Y är justerbara.
Man får dock själv läsa den förvanskade texten och avgöra om det är enkelt eller svårt att förstå den. Så mycket för vetenskapligheten.:-)
Default-texten är Mats Anderssons ursprungstext (något justerad). Testa gärna med andra texter och språk.
Här är alltså Reading scrambled words.
Frågor: Är det någon som verkligen läst den undersökning man skriver om? Finns det en sådan? Var?
En vidareutveckling vore kanske att göra en "inverterad" Levensthein edit distance (länken är till google) för att se hur blandad den förvanskade texten kan vara med små värden för X och Y.
Uppdatering 1
Jag kom lite senare på att ett relaterat program är AnaCheck, som givet en slik förvanskad text går igenom en ordlista för att lista ut vilka ord som kan vara korrekta. Glöm inte att kontrollera att korrekt språk är valt.
Uppdatering 2
Och så finns det en tråd på slashdot som diskuterar detta och liknande fenomen..
Uppdatering Blå
Under inspiration av Niklas Johanssons kommentar har jag nu lagt till en möjlighet att sortera de icke-fixa bokstäverna. Tack Niklas!
Uppdatering Kablagebyte
Så har vi tydligen fått tag i undersökningen. DN-artikeln Bkasotvsodnrnig sknaar bydetslee skriver mer om detta.
Enligt artikeln är det undersökningen Sublexical units and the split fovea av Richard Shillcock och Padraic Monaghan, University of Edinburgh, January 10, 2003.
Jag har dock inte läst papret ännu...
Tack till Mats Andersson som hittade DN-artikeln (hans kommentar finns här).
Posted by hakank at 08:57 EM Posted to Program | Comments (7)
juli 29, 2003
Humor och kreativitet
Peter på Tesugen.com skrev idag om kreativitet och humor. Här är några vidare-tankar om detta. Möjligen är det ett litet avsteg från det Peter primärt tänkte på.
För den som är är intresserad av humor och kreativitet rekommenderar jag att läsa Arthur Koestlers Act of Creation, där han diskuterar kreativitet på olika plan, däribland humor.
Sedan många år har jag själv varit intresserad av humor, speciellt vitsar och dess tekniker. Se t.ex. min lilla Vad är en vits - en webbessä där jag skriver lite om vitsens tekniker. Det finns några ytterligare litteraturreferenser. (Jag skrev den som en uppgift i Människa-Dator-Interaktion 1995, då vi skulle skriva en "interaktiv uppsats" i HTML.)
Ett av mina projekt är att skapa "roliga ord". Några av försöken:
- Word Meld, trixar med ordens prefix och suffix:
- New Markov Words , använder Markovkedjor
Möjligen är de genererade orden inte alltid (dvs sällan!) roliga, men ord som analysmodellerstrand, skapad av Word Meld (på ordet kjellerstrand) är lite skoj.
Problemet är, just som Peter skrev, att göra urvalet av de roliga orden. Jag har dock några svävande idéer hur man gör sådana urval. En av idéerna påminner om Darwinian Poetry (tack Kalle för påminnelsen), dvs att generera en massa ord varvid någon (t.ex. jag själv) värderar dem efter hur roliga de är, vilket genererar en massa data om "bra" och "dåliga" ord. Så kommer en data-mining-fas där man förhoppningsvis hittar några relevanta parametrar, som man sedan kan använda för att generera nya ord. Håhåjaja.
Intressant nog finns det ett forskningsområde om datorgenererad humor (computational humor). Några som har skrivit rätt mycket om detta är Kim Binsted och Graeme Ritchie.
Avslutningsvis: Bob Hope: RIP!
Posted by hakank at 02:24 FM Posted to Humor | Program
juli 09, 2003
Socialt avstånd - och semantiskt
Råkade stöta på lite artiklar om något som väl kan kallas för socialt eller psykologiskt avstånd.
Copycat waitresses get bigger tips refererar en undersökning som - enligt artikeln - är den första som studerar hur härmning av ett beteende påverkar den härmade. Här studerashur dricksen på en restaurang påverkas av hur kyparen beter sig.
En "related stories" var Help for names' sakes. When seeking help from a stranger, ask someone who shares your name: people are more likely to assist a namesake, an e-mail study has revealed. ...About 12% of those sharing both names responded, compared with less than 2% of people sharing none. A shared first name or surname got a smaller response, but was better than nothing.
Så man kanske skulle ta tillbaka namnet Andersson (som min far hette innan de bytte till Kjellerstrand). Enligt Eniro, privatpersoner finns det 250 stycken "Håkan Andersson". Vilket ju är avsevärt fler än 1.
En annan relaterad artikel: We like the look of lookalikes: We're more likely to trust someone who looks a bit like us, says a psychologist. The same tendency may have helped our ancestors to help their kin.
En liten aside: Själv har jag sedan länge varit fascinerad av semantiska avstånd, dvs hur nära ord är till andra och även hur man skapar ord som liknar varandra, speciellt vitsar. Se t.ex. mina små program Nearest words eller New Markov Words II eller Markov generated proverbs.
Posted by hakank at 10:15 FM Posted to Diverse | Kognitiva illusioner | Komplexitet/emergens | Program
juni 28, 2003
Uppdaterat program: AnaCheck
Uppdaterade programmet AnaCheck (Anagramator) som gör en kontroll av enords-anagram i en text. Förändringarna:
- bytte ut orddatabasen mot en mycket större
- en liten fix så att inställning av svenska språket bibehålles till nästa sökning.
Tack "Henke" för förslagen! En annan önskad utökning var att man kan använda jokrar i texten, t.ex. en text som innehåller "temt?olep" (där "?" är en joker) ska ge "totempåle". Ska vid tillfälle fundera hur man löser detta på ett tillräckligt effektivt sätt (brutalversionen är mycket enkel att göra men är för långsam).
Historien bakom detta program: Det skapades 1998 under en företagstävlig kallad Uppdraget (inte TV-programmet) där olika företag tävlade i att utföra praktiska uppdrag och lösa teoretiska problem. Ett av problemen jag fick på min lott var en text som till synes var helt oförståelig. That's it. Texten visade sig, efter en liten stunds funderande, bestå av ord där bokstäverna var omkastade (alltså anagram). En kommandoradsversion av AnaCheck skrevs för att automatisera o-omkastningen och gav tillräckligt bra resultat så att man kunde förstå texten: En kunskapsfråga som var lätt av besvara.
Så föddes ytterligare ett useless program.