« mars 2005 | Main | maj 2005 »
april 28, 2005
Mailen konstig
Till dem som berörs: Sedan middagstid har mailen strulat lite (både in och ut). Vet inte när den funkar tipp-topp igen.
Peter: Tack för länken. :)
Uppdatering
Nu funkar mailen igen. Tyvärr lite väl bra...
Posted by hakank at 04:36 EM Posted to Diverse | Comments (3)
Sista ledtråden i Aprilpyssel-gåtan
Aprilpyssel närmar sig sig slut. På söndag (1:e maj) kommer jag att avslöja vad alla ledtrådar betyder och vad de inte betyder samt ge det "korrekta" svaret (dvs det jag tänkt mig; det finns måhända alternativa tolkningar).
Här är sålunda den sista ledtråden. (URL:en för detta program efter några körningar är möjligen ytterligare en ledtråd.)
Posted by hakank at 06:58 FM Posted to Diverse
april 26, 2005
Johan Asplund "Genom huvudet" (några andra av Asplunds böcker nämns och rekommenderas också)
Genom Huvudet: Problemlösningens socialpsykologi (ISBN: 9173744034) av Johan Asplund är en underbar bok som till ytan analyserar lösning av problem (gåtor) men har en underström (eller är det en överström?) av en stark kritik av både kognitiv psykologi och traditionell AI för att dessa endast studerar de mänskilga förmågorna isolerat från de sociala sammanhangen där förmågorna verkar.
Lösning av de konstruerade gåtor som Asplund främst behandlar är i och för sig rätt speciella genom att de har vissa typiska drag som mer naturlig problemlösning (t.ex. en nobelpristagares forskning) oftast saknar:
* det finns en mänsklig konstruktör av gåtan
* det finns någon som presenterar gåtan som en gåta
* problemlösaren inser oftast snabbt att det är en gåta och ställer sig s.a.s. i gåt-mode.
* en gåta behåller man inte utan den är till för att ges bort, det är en gåva (underbart!). Varpå den som tidigare var gåt-mottagare nu blir gåt-givare.
Här visar sig alltså den sociala dimensionen av gåtlösningen. Denna typ av problemlösning är inget som sker isolerat - endast "genom huvudet" - på en person utan är ett intrikat samband mellan flera personer (roller).
Det finns också vissa förväntningar hur man ska bete sig som problemlösare. Asplund menar att ingen egentligen förväntar sig att dessa gåtor ska lösas, eftersom man har väldigt kort tid på sig att komma med ett rätt svar eller gissa (typ 10-20 sekunder). Skulle gåtan verkligen lösas blir gåtställaren besviken, och på något sätt är det sociala mönstret brutet. Min egen erfarenhet av gåtlösning är något annorlunda. De gåtor som jag faktiskt löser kan ta både kortare och lite längre tid att lösas, men nog katten ska de lösas. [Skillnaden mellan våra synsätt kan vara att Asplunds gåtor/svar levereras direkt mellan två personer, t.ex. i en frisörsalong, medan de gåtor jag tenderar att försöka lösa fås via mera indirekta medium såsom webb eller mail där gåt-givaren troligen inte har sådana förväntningar på direkt respons.]
Ovanstående struktur påminner mycket om vitsens vilket Asplund nämner i förbigående men går tyvärr inte djupare in på detta. Det kanske kommer i en senare bok? En skillnad som jag ser det är att vitsar mer sällan "löses" så medvetet som gåtor, men annars finns det stora likheter i både den tekniska och den sociala strukturen hos dessa två konstarter.
Asplund diskuterar inte bara gåtor utan vidgar diskussionerna till att gälla schack, som ses som ett socialt spel med många gemensamma drag av gåtlösning. Inte heller i schack löser man problem isolerat, endast "i huvudet". Man måste hela tiden ha en motståndare och dennes möjliga strategier i tanken när man planerar sitt nästa drag. En bra poäng: Om båda spelarna visste de bästa dragen i samtliga positioner vore schack förfärligt tråkigt.
Ett av bokens trevligaste kapitel är kritiken av AI:s isolationism, där framförallt två saker diskuteras: Turing testet (en riktigt länksamling finns här) som är en av (traditionell) AI:s stora hörnpelare och Searles tankeexperiment med Det kinesiska rummet.
När jag först blev uppmärksam på boken trodde jag den skulle vara sprängfylld med olika gåtor och tips hur man löser dem. Det är den inte, det är helt enkelt inte en sådan bok.
(En betydlig kortare version av denna recension finns att hitta för den som söker.)
Gåtor och Asplund är två begrepp som hör tätt ihop - i alla fall i mitt huvud - sedan han skrev Om undran inför samhället (Bokuslänk, ISBN: 9170060002) där flera exempel på social forskning och dess problem förklaras med just gåtor. "Om undran ..." påverkade mig mer än vad jag ofta inser, t.ex. genomgången av aspektseende (som i och för sig en gammal kursbok Jan Andersson och Mats Furberg Språk och påverkan också betonande) och lösningen av "gåtor". Här diskuteras både sociologiska teorier och pusseldeckarnas sätt att lösa problem, i en synnerlig salig blandning. Ett speciellt påverkansfullt kapitel var analysen av Marcel Duchamps tavla (La mariée mis à nu par ses cëlibataires, meme, vilket översätts till "Bruden avklädd av sina ungkarlar"). Denna bok rekommenderar naturligtvis också.
Asplund är en sådan där som ställer de intressanta frågorna och sådant fascineras jag alltid av. Läs här bara hur han börjar sin Om hälsningsceremonier, mikromakt och asocial pratsamhet (min emfas):
Antag att du råkat i konflikt med din granne. Ni har försökt att lösa konflikten med misslyckats. Er tidigare vänskap har förbytts i ovänskap. Dock stöter ni fortsättningsvis jämt och ständigt på varandra; ni möts vid tomgränsen, på gatan osv. På vilket sätt framgår det av dessa konfrontationer att du och din granne numera är ovänner? Den frågan kan med största lätthet besvaras av var och en. Att ni är ovänner framgår av att ni har slutat hälsa på varandra.
Hur gör man när man låter bli att hälsa på sin granne?
Posted by hakank at 07:53 EM Posted to Böcker | Diverse vetenskap | Husgudar | Comments (5)
april 25, 2005
Steven D. Levitt, Stephen J. Dubner: Freakonomics : A Rogue Economist Explores the Hidden Side of Everything
I höstas läste jag en del om ekonomen Steven Levitt och sedan jag lite senare fick reda på att han höll på att skriva en bok har jag varit mycket förväntansfull. Boken Freakonomics (Bokus, ISBN: 006073132X) kom ut för några veckor sedan och är nu läst. Här är några kommentarer.
Det har skrivits mycket om Freakonomics i amerikansk traditionell media och naturligtvis även i bloggar (se t.ex. Technorati), men i Sverige har det än så länge varit tyst. Det enda som kommer vid en googling på freakonomics vid "Sök på svenska" är Dennis Josefssons (Sänd mina rötter regn) blogganteckning Abort som brottsbekämpning som skrevs för några veckor sedan (där finns även lite vidarelänkar).
Det som mest inspirerade i boken var författarnas (läs: Levitts) ifrågasättande av "vedertagna sanningar" ("conventional wisdom") kring mer eller mindre vardagliga företeelser och deras orsakssamband. Jag vet inte om han har rätt i allt det han skriver (mycket har blivit ifrågasatt av andra forskare och experter) men det känns på något sätt som en frisk vind i samhällsdebatten.
I ett av inledningskapiteln förklaras författarnas världsbild:
This book [...] has been written from a very specific worldview, based on a few fundamental ideas:
* Incentives are the cornerstone of modern life. [...]
* The conventional wisdom is often wrong. [...]
* Dramatic effects often have distant, even subtle, causes. [...]
* "Experts" - from criminologists to real-estate agents - use their informational advantage to serve their own agenda. [...]
* Knowing what to measure and how to measure it makes a compicated world much less so. If you learn how to look at data in the right way, you can explain riddles that otherwise might have seemed impossible. Because there is nothing like the sheer power of numbers to scub awyay layers of confusion and contradiction.
[...]
So the aim of this book is to explore the hidden side of ... everything.
Vilket naturligtvis är ett mycket lovvärt. Även om författarna inte utforskar allting visar de på några metoder och tankesätt som gör att man kan bättre kritiskt granska våra gamla vedertagna sanningar eller nya forskarrapporter.
Sista kapitlet avslutas med följande angående bokens röda tråd:
Will the ability to think [sensibly about how people behave in the real world] improve your life materially? Probably not. [...] But the net effect is likely to be more subtle than that. You might become more skeptical of the conventional wisdom; you may begin looking for hints as to how things aren't quite what they seem; perhaps you will seek out some trove of data and sift through it, balancing your intelligence and your intuition to arrive at a glimmering new idea.
En annan sak som tilltalade mig var just denna starka koppling till dataanalyser. Speciellt avnittet hur de bar sig åt för att analysera fusk bland lärare och hos Sumo-brottare står ut här. Tyvärr görs det mestadels en antydan om de metoderna som använts. Mer om detta står dock i respektive artiklar som Levitt skrivit, se t.ex. länkarna nedan (alla har inte detaljstuderats). Det var också roligt att läsa hur Levitt på olika slumpvisa vägar fick tag i en datamängd och sedan fick uppslag till en artikel.
Jag måste nog inflika att boken inte alls är full av matematiska formler (det finns inte en enda formel såvitt jag såg), men det finns en och annan tabell med siffror som man diskuterar utifrån.
Andra saker som gås igenom i boken:
* vad som orsakade nedgången av brott i USA på 90-talet. Levitts tes att detta till stor del var en konsekvens av abortlegaliseringen har blivit mycket omstridd (se t.ex. Dennis länk ovan). Kapitlet går även igenom flera andra troliga (och mindre troliga) orsaker.
* Ku Klux Klan, historiken och hur deras hemligheter avslöjades. I samband med detta görs en diskussion om asymmetrisk information och hur webben har förändrat experternas informationsövertag. (Ni får själv läsa på vilket sätt detta hör ihop.)
* vad hos föräldrarna och deras uppfostran som påverkar sina barns (skol)utveckling mest. Här raljeras rätt kraftigt med de för tillfället vedertagna sanningarna. Boken ger antydningar om att det inte är så mycket vad föräldrarna gör utan mer vad de är (har själv bra utbildning, bra socialt ställt osv) som påverkar mest. Så säger i alla fall den data som analyserats, enligt Levitt.
* risker och hur vi förhåller oss till sådana, t.ex. orsaker till att barn förolyckas; flygresor vs. bilåkande.
* hur en crack-liga är organiserad. Kapitlet har den underbara titeln "Why do drug dealers still live with their moms?". Svaret är att de flesta inom en crack-organisation har det väldigt dåligt ställt och måste bo hos sina föräldrar. Det är bara ett fåtal i toppen av organisationen som tjänar mycket.
Kännetecknande för kapitlen är att man utgår från datamängder som analyserats grundligt. Även om många troligen är starkt kritiska till Levitts (och dennes samarbetspartners) slutsatser måste det vara en bättre start för en diskussion att, om möjligt, utgå från empirisk data i stället för att skapa teorier "i det blå", något som ekonomer och statvetare gärna gör (menar Levitt).
Slutkommentar:
Vissa kapitel var mycket intressanta för dess diskussioner och historik av olika samhällsfenomen (med viss tonvikt på amerikanska förhållanden), t.ex. om crack-gängens organisation och Ku Klux Klan.
Andra kapitel var även intressanta ur dataanalys-synpunkt, t.ex. fuskdetektion, genomgången av hur mycket av föräldras beteende som påverkar barnens vidare utveckling. (I samband med det senare beskrivs även en studie om/hur namngivning av barn påverkar barnens vidare utveckling och även hur namngivning fluktuerar i samhället. Här blir det tyvärr lite för rapande av namnlistor sida upp och ned.)
Det är en inspirerande men oroande bok: Hur många av våra vedertagna sanningar är inte sanna?
Lite mer att läsa:
Steven Levitt
Stephen J Dubner
Författarnas gemensamma blogg
Introduktionen och kapitelutdrag från boken
Några artiklar av författarna.
Dubners New York Times-artikel The Probability That a Real-Estate Agent Is Cheating You (and Other Riddles of Modern Life) (3 Augusti 2003, PDF) är ett idolporträtt av Levitt och citeras ofta i boken. Såvitt jag förstår var det i samband med denna artikel som de två fattade tycke för varandra.
Flera av Levitts papers finns nedladdningsbara på Recent Publications och Working Papers, men tyvärr kräver de mestadels registrering etc.
Så här är några papers eller artiklar som hittades på andra ställen. En del av den nämns i boken och/eller NYT-artikeln.
Falling Behind (PDF)
Understanding The Black-White Test Score Gap in the First Two Years of School
Rotten Apples: An Investigation of the Prevalence and Predictors of Teacher Cheating (PDF)
To Catch a Cheat (PDF)
How do markets function? An empirical Analysis of gambling on the national football league (PDF)
An Economic Analysis of a Drug-selling Gang's Finances (PDF)
The Impact of Legalized Abortion on Crime (PDF)
Why are Gambling Markets Organized so Differently than Financial Markets? (PDF)
Is Black Culture a Cause or Consequence of Racial Inequality? An analysis of Names (PDF)
The Changing Relationship between Income and Crime Victimization (PDF)
Op-ed piece on swimming pools vs. guns as the most dangerous weapon
Posted by hakank at 08:25 EM Posted to Spelteori och ekonomi | Comments (2)
april 22, 2005
Internetworlds bloggomröstning. Tack, ni 8!
I går kom resultatet av Internetworlds omröstning av "Sveriges bästa bloggar". Grattis till vinnaren Johan Norberg och grattis till alla som kom med på listan.
Stort tack!
Stock tack ni 8 stycken som tycker att detta är Sveriges bästa blogg. Det är mycket för er jag skriver när jag väl skriver; jag tänker på er ofta. På olika sätt har 4 av dessa personer identifierats, så det är spännande att ha 4 (8 - 4 = 4) för mig okända - vågar man skriva? - "beundrare".
Om du är en av de 8 och du säger de magiska orden (per realtid, mail eller kommentar på bloggen) kommer jag att bjuda på en öl eller glass beroende på väder, klockslag och ställe. Not för att förhindra fuskifikationer: Om det är fler än åtta personer som säger de magiska orden så är all bets off.
(Det var även 8 som röstade på Niklas Lundblads Kommenterat, en av mina favoritbloggar.)
Gissningstävlingen
En bloggare (och tillika vän) och jag hade en liten gissningstävling på resultatet och hur många som skulle rösta i denna tävling samt i vilken position min blogg skulle komma, om den nu kom med. Själv hade jag några rätt och några fel. Min gissning - som var fel - var att Erik Stattin och Annica Tiger skulle få flest röster. Det blev ju i stället Johan Norberg som tog toppplatsen. Annica kom på sjunde plats och Erik på trettonde.
När det gäller antal röstande var min gissning att det skulle bli 2023 röster och att min blogg skulle komma på 49 plats med 7 röster. Det blev 2029 röster och hakank.blogg kom på 45:e plats med 8 röster. En något bättre gissning, alltså.
(Not: Någon kan tycka det är förmätet att jag trodde att hakank.blogg skulle komma med på listan överhuvudtaget. Det berodde på att bloggen var listad i den lista som Internetworld listade som röstbara bloggar. Det fanns även möjlighet att rösta på en icke-listad blogg, vilket många gjorde. Det var 212 bloggar som fick åtminstone en röst.)
Antal röstande
Många verkar ha trott att det skulle bli många fler röstande (siffror på ett par tiopotenser högre har antyts i eftermälena), men jag tror att även om det skapas flera bloggar nu än tidigare är det navelskådande intresset för bloggning fortfarande begränsat. Vilket kanske är ett sundhetstecken: Man ska inte behöva vara intresserad av tekniken eller bloggningens sociala eller politiska roll för att själv blogga. Jag tror också det är många som läser bloggar utan att se det som en blogg, vilket nog också är ett sundhetstecken. Till sist, vänder sig Internetworld inte till en rätt begränsad läsekrets?
En röstningsmodell vågas på
Om man skulle våga sig på en modell: En viss andel av rösterna var svenska bloggare som är intresserade av bloggning som fenomen, politisk företeelse etc. De röstade naturligtvis. Låt oss säga att det finns 100 sådana bloggare. Deras mest aktiva icke-bloggande läsarna röstade naturligtvis också. (En aktiv icke-bloggare är en sådan som eventiellt skriver kommentarer hos sin favoritblogg eller kommunicerar via mail etc, men har ingen egen blogg.)
Låt oss klämma till med att varje blogg har i genomsnitt 15 icke-bloggande aktiva. Det gör 100 + (100 * 15) = 1600 röster. Till detta finns det 429 röster som är "kompisröster", dvs från vänner och bekanta som egentligen inte läser bloggar. Inalles 100 + 1500 + 429 = 2029 röster. De exakta siffrorna är naturligtvis tagna ur luften men skulle kunna stämma.
Det man kan kritisera i denna modell är att fördelningen av aktiva icke-bloggare per blogg är ojämn men sett som genomsnitt skulle ovanstående stämma.
(En alternativ modell vore att samtliga de 2029 röstande var bloggare. Men jag vet i alla fall en (1) icke-bloggare som röstade, så där faller den modellen.)
Går det att tävla i bloggeri? Eller ska det ses som ryggdunk?
Så till den obligatoriska kommentaren om det går att tävla i sådant här eller inte. Det beror naturligtvis på vad det man tror att tävlingen går ut på. Det kan knappast vara att rösta fram "bästa" bloggen där "bästa" bygger på något objektivt givet kriterium, eftersom det inte ens finns någon objektiv och edligen stadgad definition av vad en blogg är.
Snarare ser jag det som ryggdunkningar och uppmuntringar från trogna läsare. I verkliga livet kan man dock dunka fler än en rygg.
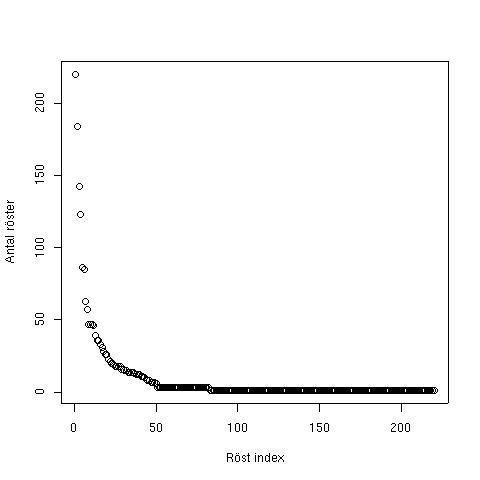
Lite bilder
Det skulle ha varit roligt att se alla de 212 bloggarena samlade på ett samlat fotografi, men det är naturligtvis ganska svårt. I stället visas en graf över röstandet där y-axeln är antal röster sorterat på antalet röster. Notera speciellt den långa svansen, dvs de många bloggar som fick mindre antal röster. [Jag vet inte den exakta fördelningen av de 34 stycken 2-5-rösterna, så dessa klumpades ihop till 3-röster för att förenkla.]
En tolkning av den långa svansen vågas på
Om man skulle våga sig på en tolkning av detta vore det att bloggosfären är spretigare än vad i alla fall jag trott. Detta skulle innebära att "den svenska bloggosfären" numera inte är så homogen som det ibland verkar antydas (eller kanske tidigare har varit). Det finns alltså inte en utan flera "bloggosfärer". Troligen är detta också ett sundhetstecken, dvs att det inte är en endast en liten klick som alla läser utan i stället många klickar (möjligen små) som lever parallellt.
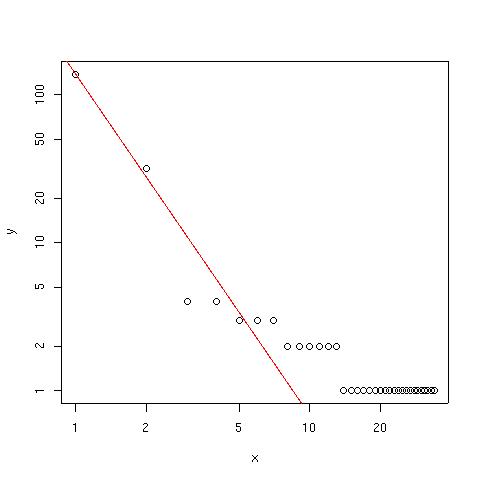
log-log-plot
Eftersom det är en kurva som visar att ett fåtal har många röster och många med färre röster, kunde jag inte låta bli att göra en log-log-plot på antal röster vs antalet bloggar som fick detta antal. Det fanns t.ex. 3 stycken bloggar som fick 47 röster, 2 som fick 8 etc, 138 som fick 1 röst etc. Den röda linjen visar den linjära koefficienten för log-log-skalan. (Här skulle man kunna vara ansträngt rolig och kalla detta för en blog-blog-plot. Vilket härmed gjordes.)
De vilda planerna
Det fanns även vilda planer att göra en betydligt djupare analys av datan genom att försöka korrelera röster till olika attribut hos bloggen såsom inriktning på bloggen, bloggarens kön, geografisk placering, start av blogg, genomsnittligt bloggningar per månad etc.
Avslutning, i ett något annorlunda tonläge
Men tiden räcker ibland inte till till alla de roliga projekt som finns i den skog som kallas livet. Ibland får man nöja sig att dofta på en enskild blomma eller lyfta på ett enskilt blad för att ana hur ängen doftar och hur ängen växer, vilket ofta räcker för att bli påmind om dess storhet.
Posted by hakank at 10:12 EM Posted to Blogging | Comments (3)
april 14, 2005
Amazons "Statistically Improbable Phrases" (SIPs)
I två separata maildiskussioner (med Peter Lindberg och Simon Winter) har Amazon.com:s "Statistically Imprabable Phrases" (SIPs i folkmun) diskuterats. Den enda svenska text jag har hittat om detta är Erik Starcks notis Amazon testar Statistically Improbable Phrases (med en kommentar av Simon).
Det känns som det är dags att göra en liten sammanfattning (och ett gemensamt ställe att kommunicera findings).
Sedan några veckor har flera böcker presenterats med vad Amazon.com kallar för "Statistically Improbable Phrases". Det är sådana fraser som används ofta i en viss bok men sällan i andra böcker. Så här förklarar de själva:
Amazon.com's Statistically Improbable Phrases, or "SIPs", show you the interesting, distinctive, or unlikely phrases that occur in the text of books in Search Inside the Book. Our computers scan the text of all books in the Search Inside program. If they find a phrase that occurs a large number of times in a particular book relative to how many times it occurs across all Search Inside books, that phrase is a SIP in that book.
För t.ex. Malcolm Gladwells The Tipping Point finns SIPparna: social epidemics, transactive memory, mouth epidemics, teenage smoking. Man kan notera att frasen "tipping point" inte finns med, vilket beror på att det används i och för sig ofta i Gladwells bok, men finns även ofta i andra böcker.
Tanken med sådana SIP:ar verkar vara att visa på utmärkande drag i boken, men jag är tveksam till hur nyttiga de egentligen är för detta ändamål. Anledningen till tveksamheten är att det verkar vara svårt att göra en bedömning av bokens innehåll med hjälp av endast dessa fraser. Det känns rätt mycket som en titta-vad-vi-kan-göra-funktion (som i och för sig är cool). I och för sig är jag benägen att ändra mig när jag ser detta.
Däremot ger möjligheten att SIP-surfa, dvs att klicka till andra böcker med samma fraser, ännu ett trevligt sätt att upptäcka nya böcker. Vi har nog bara sett början på detta...
Principen bakom SIPs är inte ny. T.ex. får man väl anse att det är en variant (konceptuellt i alla fall) av hapax legomenon, dvs helt unika ord i en text. Se även denna längre artikel.
Mer generellt änvänds (troligen) en variant av Term Frequency / Inverse Document Frequency (TFIDF), som det finns en hel del skrivet om. Det stora med Amazons implementation är naturligtvis att det är publikt surfbart och att metoden används på en stor mängd texter (böcker).
Inspirerad av allt detta började vi (Peter, Simon och jag i separata) att fundera på hur man bäst gör egna varianter för våra respektive blogganteckningar, där en bok skulle motsvaras av en blogganteckning.
Peter tipsade om ett litet Pythonprogram (dess notis), men som endast arbetade med "fraser" på ett enda ord, vilket inte är så skoj.
Själv kikade jag i helgen på ett Perl-paket som Simon fått nys om: Ngram Statistics Package (NSP), på CPAN heter det Text::NSP. Efter en del föreståendeskapande lekar med detta började de mer seriösa arbetet, men det kräves mycket tråkigt filtreringsarbete och annat så projektet lades på hyllan, i alla fall för tillfället.
Jag är nu, efter de trevlande inledande försöken, till viss del tveksam hur mycket detta projekt egentligen ger (förutom leken, utmaningen och äran) eftersom en blogganteckning innehåller så pass lite text att det kan vara svårt att det blir intressant. I och för sig påverkas jag inte mycket av nyttan av ett projekt. :-)
Troligen kommer man fram till att det finns en stor mängd ord som endast förekommer i en enda blogganteckning (dvs blogg-hapax legomenon), såsom namn eller begrepp, och så finns det en stor mängd fraser som har en frekvens som motsvarar det vanliga språkbruket. Frågan som är intresserant att undersöka är om det finns tillräckligt många ord som befinner sig mellan dessa två frekvenstyper och därmed betecknar något "statistiskt osannolikt" (och förhoppningsvis överraskande) om en blogganteckning.
En utökning av detta vore att arbeta med samtliga texter för en blogg och jämföra frasfrekvenserna med andra bloggar, vilket nog skulle ge bättre utdelning.
Andra finesser som Amazon infört den senaste tiden är presentation över vanligast förekommande ord (concordance), olika typer av textstatistik och complexity. Exempel på sådant finns t.ex. här (Peters exempel).
Ytterligare:
Google-sökning på "Statistically Improbable Phrases"
Det finns en Perl-modul som beräknar olika textindex för engelska texter. Lingua::EN::Fathom.
Uppdateringar
Blind "Jonas Söderström" Höna har även skrivit om detta:
Amazon letar fram "osannolika fraser" i böcker samt Mer på amazon: de hundra vanligaste orden
En annan sak. Böckerna beställes naturligtvis via Bokus:
* Malcolm Gladwell: The Tipping Point
* Lynne Truss: Eats, Shoots & Leaves - The Zero Tolerance Approach to Punctuation
Posted by hakank at 08:55 EM Posted to Böcker | Machine learning/data mining | Språk
Digital grusväg - ännu senare nummer ute!
Husorganet Digital grusväg har återigen kommit med ett ännu mera senare nummer (1/2005 PDF).
Denna gång har specialstuderats sophinkars placering i köket. Från introduktionen:
När man vill hjälpa till att duka av bordet hemma hos en bekant, behöver man ofta slänga något i sophinken. Problemet är var sophinken är placerad. I de flesta hem finns den i skåpet under vasken, men bakom vilken av luckorna?
Undersökningens syfte var att se om det finns några uppenbara mönster bakom placeringen av sophinken i köket.
Här kommer inte att avslöjas det spännande resultatet, det får läsaren läsa själv. Däremot kan nämnas att rapporten är avundsvärt och unikt naket ärlig: Studien inbjuder till vidare forskning för att höja kunskapsnivån till en praktiskt användbar nivå. Studien konstaterat skillnader utan att kunna förklara dem.
Rapporten avslutas som sig bör med förslag till framtida studier.
Om man skulle drista sig att komma med någon kritik av undersökningen skulle det kunna vara att sophinkhinksägarens (vänster|höger-)hänthet saknas som parameter, eller snarare: den mest frekventa häntheten i hushållet samt hänthetens beskaffande, dvs om man vill öppna skåpsdörren med sin hänthetshand eller vill man slänga soporna med denna hand (cf. skyfflar en person X in mat i munnen med sin häntheta hand eller skär denne upp maten med hjälp av den).
Om det fortfarande skulle dristas med kritik kunde en annan sak nämnas, nämligen frågan om det finns något bakom den i föreliggande fall andra skåpluckan som är ännu viktigare att placera där det i så fall placerats, t.ex. tidningar för snabb access, städverktyg eller diskverktyg för ännu snabbare access, andra verktyg, eller en blå leksaksbil som används vid övriga tillfällen. Sophinkens placering och de mönster som hittades i studien skulle i så fall endast vara ett förvisso mönster, men såsom Kants teori förutspår endast visar de för oss endast flyktiga fenomen och icke Tinget i sig.
Det skulle möjligen även vara intressant med en spelteoretisk modell där man studerar fall där sophinksägaren inte vill att personer med mindre sophinksbekantskap ska hitta sophinken vid första försöket.
Läs även:
Tidigare nummer
En kort redogörelse om namnet "Digital grusväg" (främst i kommentarerna).
Posted by hakank at 05:58 EM Posted to Statistik/data-analys | Statistik/data-analys | Comments (2)
april 12, 2005
Duncan Watts om komplexa nätverk och Steve Borgatti om sociala nätverk
Två Taicon (The Trans-Atlantic Initiative on Complex Organizations and Networks)-föreläsningar i ett.
Duncan Watts börjar med att prata om forskning inom komplexa nätverk i Six Degrees: The Science of a Connected Age. Föredrag börjar cirka 10 minuter in i bandet, efter lite olika introduktioner.
Sedan talar Steve Borgatti om forskning inom sociala nätverk som en kommentar till Watts föreläsning. Lite märkligt att det inte står något om hans föreläsning på sajten. Borgatti är - forutom f.d. ordförande i INSNA (International Network for Social Network Analysis) - även skapare att det kompetenta programmet Ucinet, ett av mina två favoritprogram för sådana analyser. (Pajek är det andra favoritprogrammet.)
I morgon (13 mars 2005, 18:15 lokalt Zürich såvitt jag förstått) håller John Holland ett föredrag om Agents: Specializations for Language. Det ska bli intressant.
För vidare inom om komplexa och sociala nätverk, se även kategorin Social Network Analysis and Complex Networks samt samlingssidan Social Network Analysis och Complex Networks - En liten introduktion.
Posted by hakank at 11:20 EM Posted to Social Network Analysis/Complex Networks
april 05, 2005
Skånsk bloggaremiddag i maj
Daniel Olovsson på minmening.com föreslår att nästa skånska bloggaremiddag blir i maj.
Klicka dit för mer detaljer.
Posted by hakank at 09:30 EM Posted to Blogging
april 04, 2005
Begreppslig utredning och försvar att använda "papret" i föregående blogganteckning
Snabbt som rackarn mailade Daniel Olovsson mig och frågade om "Papret", det allra första ordet i föregående anteckning, var felstavat, varpå nedanstående utläggning kändes påkallad. Notera att det är mina intuition kring dessa ord och de (intuitionerna) är naturligtvis inte spikade i sten.
Det var ingen felstavning eftersom det är en försvenskning av det engelska "paper" (med ett "p"). "pappret" låter inte riktigt lika bra i min bok. Några tänkbara kandidater skulle kunna vara:
* "uppsats", men det låter som en sådan där sak man skrev i högstadiet
* "vetenskaplig artikel", är lite för klumpigt
* "artikel" som ensamt ord är jag allergisk mot eftersom det används i alldeles för många sammanhang: (tidnings)artikel, (blogg)artikel, (produkt)artikel, (p)artikel etc.
* "skrivning", lite väl allmänt och används nog mer för att beteckna antingen de proven man hade i gymnasiet/universitetet eller för att betona en språklig figur
* "studie" respektive "vetenskaplig studie" är i och för sig rätt bra, men refererar - enligt min uppfattning - inte bara till själva dokumentet utan till hela studien (undersökningen), och dokumentet är endast en del av av denna. Mer korrekt skulle nog vara "Studien X visade sambanden A, B och C, vilket sålunda har nedtecknats i dokumentet P", vilket är något för långt för att inleda en bloggnotis.
Håller naturligtvis med om att en rak översättning av engelska termer utan att tänka på att de kan förvirra är inte bra. Jag är dock inte ensam om ofoget, men det är ingen ursäkt att skriva förvirrande. För detta (o-allenaheten) anför jag google.
Alla dessa förekomster kan inte vara stavfel, eller kan de det?
OK, jag ska bättra mig.
Posted by hakank at 06:52 EM Posted to Språk | Comments (13)
Analys av Google Answers
Papret Why Voluntary Contributions? Google Answers (PDF) av Tobias Regner är en analys av Google Answers och förhållande mellan pris, "tipping" och reputation utifrån data mellan juli 2003 och januari 2004. Notera att en del av papret är rätt tekniskt (formler och slika saker).
Abstract:
We study the pricing and tipping behaviour of users of the online service `Google Answers'. While they set a price for the answer to their question ex ante, they can additionally give a tip to the researcher ex post.
We develop a model that is based on reciprocal theories of social preferences pioneered by Rabin (1993) and extended by Dufwenberg and Kirchsteiger (2004). The predictions of our model are empirically tested with the field data we obtained.
The reasons for leaving a tip are analysed. A significant amount of users are motivated by social preferences. We also find strong support for reputation concerns. Moreover, researchers appear to adjust their effort based on the user's previous tipping behaviour.
We conclude that an endogenous incomplete contracts design encourages people to contribute voluntarily. This is motivated by reciprocity when people are socially minded, but also generally by strategic behaviour to build up a good reputation. Efficiency is increased when contracts are left open deliberately as high effort is sustained.
Keywords: social preferences, reciprocity, moral hazard, reputation, internet
En kort summering från introduktionen:
About 25% of all answers have been tipped and the three main conclusions from our empirical analysis follow. The more questions users ask over time the more likely they are to tip. Thus, there are reputation concerns that make people tip. It seems that they aim to build up a fine reputation in order to encourage good effort of researchers for future questions. Naturally, individuals have this concern no matter what their preferences are. Moreover, even single users tip, though: around 18%. This clearly deviates from self-interest. Hence, social preferences of some kind have to be involved. Finally, tipping motivated by social preferences or out of reputation concerns seems to pay off. Our data confirms that researchers take the past tipping behaviour of users into account and put more effort into the answer, if the user has frequently tipped before. The higher effort increases the benefit of the user and the researcher gets fairly compensated for the extra effort.
Via nep-evo mailinglista.
Posted by hakank at 05:28 EM Posted to Spelteori och ekonomi